Базы данных (Проектирование реестра недвижимости)
Нужно узнать пункт закона?Статьи в Справочнике состоят из параграфов, почти каждый из которых сопровождается соответствующими цитатами из нормативных правовых документов. Такие параграфы отмечены зеленой или желтой линией (подробнее). Чтобы показать цитаты, нажмите на иконку « » справа от текста. |
- Пространственный объект (геообъект, геоинформационный объект, географический объект)
Природные, природно-антропогенные, антропогенные и иные объекты (в том числе здания, сооружения), местоположение которых может быть определено, а также естественные небесные тела.
До 01.04.2024 — природные объекты, искусственные и иные объекты (в том числе здания, сооружения), местоположение которых может быть определено, а также естественные небесные тела.
В области геоинформационных систем — цифровая модель материального или абстрактного объекта реального или виртуального мира с указанием его идентификатора, координатных и атрибутивных данных.
При описании качества пространственных данных — абстракция явления реального мира.
Заметим, что под пространственным объектом понимается как сам объект, так и соответствующая ему цифровая модель.
В качестве примера, для недвижимости вида «земельный участок» местоположение в ЕГРН устанавливается посредством определения плоских прямоугольных координат характерных точек его границ. Исторически этот процесс называется межеванием, в геоинформатике – позиционированием или локализацией.
В этот момент семантическое понимание земельного участка обретает тройственность:
- реальный пространственный объект на местности как часть поверхности земли (с ограждениями или без);
- виртуальный пространственный объект как информационная (цифровая) модель с указанием идентификатора, координатных и атрибутивных данных, сформированная в базе пространственных данных в соответствии с отраслевой моделью данных (например, по требованиям к ведению ЕГРН) или комплексной (например, по идеологии НСПД);
- визуализация информационной (цифровой) модели на производной бумажной или цифровой карте (схеме). Заметим, что образ именно модели, а не участка на местности, так как их границы хоть и могут совпадать, но являются разными сущностями.
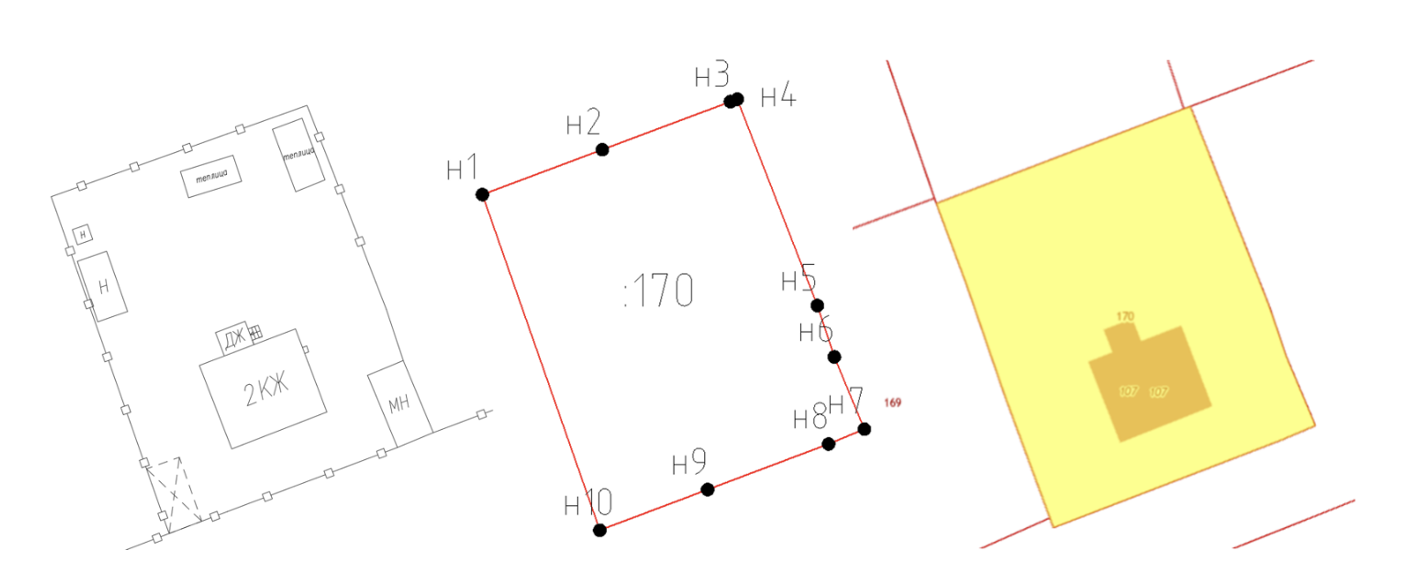
Перечень находящихся в распоряжении органов государственной власти и органов местного самоуправления сведений, подлежащих представлению с использованием координат, утвержден ПП РФ №390 от 29.03.2024 (до 01.04.2024 — РП РФ №232-р от 09.02.2017), например:
- места нахождения остановочных пунктов общественного транспорта (наименование остановочного пункта, вид транспорта, номер маршрута, координаты);
- места нахождения многоквартирных домов, признанных аварийными и подлежащими сносу или реконструкции, или о признании жилых домов непригодными для проживания (адрес, координаты).
Данные по перечню подлежат размещению на Федеральном портале пространственных данных в разделе Открытые данные.
- Данные (data)
В геоинформационных системах — информация, представленная в виде, пригодном для обработки автоматическими средствами при возможном участии человека.
При работе с большими данными — реинтерпретируемое представление информации в формализованном виде, пригодном для коммуникации, интерпретации или обработки.
- Пространственные данные (геопространственные данные, геоинформационные данные, географические данные, геоданные)
Данные о пространственных объектах, включающие сведения об их форме, местоположении и свойствах, данные о процессах и явлениях, в том числе представленные с использованием координат.
C 01.04.2024 в сведения также входят данные о процессах и явлениях.
В области геоинформационных систем — данные о пространственных объектах и их наборах.
Итоги комплексного изучения сферы создания и использования пространственных данных представлены в обзоре Росреестра, ВШЭ и НИИ «АЭРОКОСМОС» «Пространственные данные: потребности экономики в условиях цифровизации» (2020).
- Модель пространственных данных
Набор пространственных объектов и межобъектных связей, сформированных с учетом общих для этих объектов правил цифрового описания.
- Сведения о пространственных данных (пространственные метаданные)
Метаданные, которые позволяют описывать содержание и другие характеристики пространственных данных, необходимые для их идентификации и поиска.
В соответствии с Приказом Минэкономразвития России от 29.03.2017 №142 пространственные метаданные формируются в электронном виде в виде файлов в формате XML и содержат информацию:
- местонахождение территории;
- год создания (обновления);
- система координат;
- точность;
- формат хранения;
- наличие сведений, составляющих коммерческую, служебную или иную охраняемую законом тайну;
- организация-изготовитель;
- обладатель;
- год соответствия местности, в отношении которой они подготовлены;
- условия доступа, приобретения и использования;
- дополнительные характеристики (при наличии).
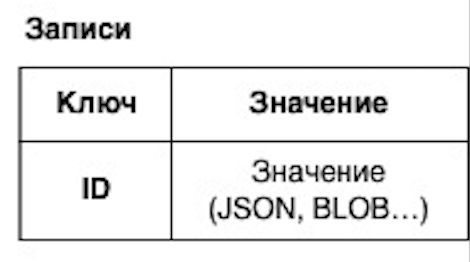
- База данных (database)
Совокупность данных, организованная в соответствии с концептуальной структурой, которая описывает характеристики этих данных и взаимосвязи между их соответствующими объектами, обеспечивая одну или несколько областей применения.
Совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
- База пространственных данных
Совокупность пространственных данных, организованных по определенным правилам, устанавливающим общие принципы описания, хранения и манипулирования данными, предназначенная для удовлетворения информационных потребностей пользователя.
Актуальный на начало 2024 года обзор зарубежной литературы по базам данных для 3D-кадастра представлен в публикации: Shahidinejad, J.; Kalantari, M.; Rajabifard, A. 3D Cadastral Database Systems—A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2024, 13, 30. https://doi.org/10.3390/ijgi13010030
Идентификатор — это последовательность символов, позволяющая однозначно идентифицировать пространственный объект или некий набор данных в информационной системе.
- Идентификатор
В информационных технологиях — последовательность символов, позволяющая однозначно идентифицировать что-либо, с чем она связана в заданном контексте.
В концепции Индустрии 4.0 — Идентичная информация, которая однозначно отличает одну сущность от другой в данном домене.
В области геоинформационных систем — уникальная характеристика пространственного объекта, присваиваемая ему пользователем или назначаемая информационной системой, которая используется для фиксации связи координатных и адресных данных пространственных объектов.
Есть разные способы обеспечения уникальности идентификаторов:
- на основе счетчика (порядкового номера записи);
- с учетом иерархии;
- статистически;
- с указанием данных;
- с хэшированием.

Использование счетчика для создания уникальных идентификаторов является одним из самых простых и интуитивно понятных способов. Счетчик представляет собой увеличивающееся целое число, которое последовательно назначается новым объектам. Основное преимущество такого метода заключается в его простоте реализации и легкости понимания. Однако, существуют определенные ограничения и риски:
- если несколько независимых систем назначают идентификаторы с использованием одного и того же счетчика, существует риск коллизий. Чтобы избежать этого, можно использовать раздельные диапазоны значений для разных систем.
- при долгосрочном использовании существует вероятность, что счетчик достигнет максимально возможного значения, особенно если идентификаторы назначаются очень часто. В таком случае потребуется принимать меры по расширению разрядности счетчика.
- в распределенных системах или при высокой нагрузке несколько процессов могут одновременно пытаться получить значение из счетчика. Если это произойдет, есть риск, что один и тот же идентификатор будет присвоен разным объектам. Например, представьте, что два процесса одновременно увеличивают счетчик с значения 1000. Без синхронизации оба процесса могут присвоить значение 1001, что создаст конфликт. Чтобы избежать этого, необходимо использовать механизмы, такие как блокировки, которые позволяют только одному процессу изменять счетчик в конкретный момент времени.

Составной ключ — это способ создания уникального идентификатора, который состоит из нескольких частей. Например, можно взять «Порядковый номер здания» и «Порядковый номер помещения в здании» и объединить их вместе, используя подходящий разделитель. Таким образом, номер помещения будет уникальным, потому что он указывает не только на само помещение, но и на здание, в котором оно находится. Пример такого составного ключа: здание «12», помещение «345», разделитель «-». В этом случае идентификатор будет, например, «12-345».
Еще один способ указания уникального составного идентификатора — это добавление домена. Домен — это область, которая определяет принадлежность объекта к определенной категории или группе. Он помогает сузить область поиска и точно определить объект.
Например, кадастровый номер месторождения, состоящий из буквенного обозначения массива государственного кадастра и числового обозначения, например: Б-34143, где Б — месторождения неметаллических полезных ископаемых.
Еще один пример использования домена — ISBN (международный стандартный книжный номер). ISBN помогает определить каждую книгу, используя уникальный номер, который состоит из нескольких частей, таких как код региона, код издательства и номер книги. Пример ISBN: 978-3-16-148410-0, где первые цифры представляют код страны или региона, далее следует код издательства и уникальный номер книги.
- Uniform Resource Name (URN)
Разновидность URI, постоянный символьный идентификатор ресурса.
Шаблон: urn:<NID>:<NSS>,
где NID — идентификатор пространства имён, NSS — специфическая строкаПримеры:
- urn:isbn:5170224575
- urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66
- urn:doi:10.1000/182
- Uniform Resource Identifier (URI)
Символьный идентификатор ресурса.
Спецификация: RFC 3986.
Шаблон: схема ":" ["//" полномочия] путь ["?" запрос] ["#" фрагмент],
где полномочия — [информация пользователя "@"] хост [":" порт]Примеры:
- https://www.example.com — URL веб-сайта.
- ftp://ftp.example.com/file.txt — адрес файла на FTP-сервере.
- mailto@example.com — адрес электронной почты.
Иерархическая структура идентификатора создает связи между объектами разных уровней, начиная от общих категорий и заканчивая конкретными элементами. Такая организация данных упрощает поиск, обработку и анализ информации.
Иерархический подход особенно полезен для систем с большим количеством взаимосвязанных объектов и данных. Например, еще одна разновидность стандарта URI — URL веб-страницы уникально идентифицирует ресурс в интернете через иерархическую структуру, начиная с доменного имени, переходя к каталогу и заканчивая конкретным файлом.
Аналогично, кадастровый номер недвижимости представляет собой последовательность, которая начинается с кадастрового округа, затем идет район и квартал, и в итоге заканчивается номером объекта в квартале.
- Uniform Resource Locator (URL)
Разновидность URI, предназначенная для идентификации ресурсов с указанием его местоположения, обычно в интернете.
В России применяется в том числе в библиографических ссылках по ГОСТ Р 7.0.5-2008.
Шаблон: <схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<URL‐путь>][?<параметры>][#<якорь>]
Примеры:
- https://www.example.com
- https://user:password@ftp.example.com:21/path/to/file.txt?download=true#section
- https://api.example.com/v1/resources?id=123&type=json&sort=desc
Уникальность идентификатора на основе статистически незначительной вероятности достигается за счёт использования различных алгоритмов и методов, которые обеспечивают практически нулевую вероятность совпадения идентификаторов. Такие идентификаторы часто применяются в распределённых системах, где требуется быстро генерировать уникальные значения без необходимости централизованного управления или синхронизации.
Примером такого подхода является использование UUID, который генерируется на основе комбинации временных меток, случайных чисел и других параметров, что делает вероятность совпадения двух идентификаторов крайне малой.
- Universally Unique IDentifier (UUID, Globally Unique IDentifier (GUID)
Статистически уникальный 128-битный идентификатор.
Спецификация: RFC 4122.
Примеры написания:
- urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6
- {f81d4fae-7dec-11d0-a765-00a0c91e6bf6}
- f81d4fae-7dec-11d0-a765-00a0c91e6bf6
Число возможных вариантов составляет 2128 = 340 282 366 920 938 463 463 374 607 431 768 211 456. Это настолько много, что вероятность коллизии при случайном задании значения статистически незначительна.

Альтернативой UUID является стандарт ULID (Universally Unique Lexicographically Sortable Identifier), предполагающий использование в идентификаторе двух компонент:
- метка времени в миллисекундах, преобразованная по специальному алгоритму в символьную строку;
- случайная строка, которая обеспечивает уникальность даже если несколько ULID генерируются в одну и ту же миллисекунду.
Главной особенностью этого подхода является возможность простой лексиграфической сортировки созданных идентификаторов по времени.
Возможно генерировать уникальные идентификаторы, которые содержат в себя некоторые данные. Примером такого подхода является Snowflake ID, который включает:
- метку времени, которая фиксирует точный момент создания идентификатора, что позволяет не только упорядочивать события, но и обеспечивать хронологический контроль над последовательностью их возникновения;
- уникальный идентификатор машины, на которой был сгенерирован идентификатор, что позволяет минимизировать вероятность коллизий в распределенной среде, где множество машин генерируют идентификаторы параллельно;
- уникальный порядковый номер, который дает возможность генерировать несколько идентификаторов за один и тот же временной интервал.

Другим интересным примером является предложенный исследователями из Бразилии URBAN PARCEL IDENTIFIER CODE, содержащий в себе:
- код административного территориального образования;
- дату;
- координаты центроида.
В идентификатор иногда включают контрольные элементы. Например:
- идентификатор записи федерального регистра сведений о населении состоит из десяти случайных цифр и двух контрольных;
- последний символ ISBN служит для проверки правильности числовой части кода издания;
- последняя цифра номера любой банковской карты является контрольным числом, рассчитанным по алгоритму Луна;
- последние цифры в ИНН, СНИЛС, ОКПО также являются контрольными.
Хеширование — это процесс одностороннего преобразования произвольных данных в фиксированную последовательность символов (хэш) — уникальный, компактный и неизменяемый код для каждого объекта. Помимо непосредственно идентификации такие коды можно использовать для отслеживания изменений в данных и контроля их целостности.
Пример: urn:sha1:3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ
- Тип данных (data type, datatype)
Определенный массив объектов данных конкретной структуры данных и набор допустимых операций, в рамках которых эти объекты данных выступают в роли операндов при выполнении любой из этих операций.
Например, целочисленный тип данных имеет простую структуру, каждый экземпляр которой, обычно называемый значением, представляет собой член заданного диапазона целых чисел, а допустимые действия включают в себя обычные арифметические операции над этими целыми числами.
Таблица — Основные примитивные типы данных
| Тип данных | Пример | Варианты реализации | Примечание |
|---|---|---|---|
| Целое число | 42 | int, integer, number… | Разные типы поддерживают числа в определенном диапазоне |
| Вещественное число с заданной точностью | 36.6 | numeric, decimal… | Задается количество знаков после запятой |
| Число с плавающей запятой | 366Е-1 | float, double, real… | Число хранится как набор из мантиссы и порядка (366·10−1) |
| Текстовый (символьный) | "Hello, world" | text, char, varchar… | Разные типы поддерживают строки разной длины |
| Дата и время | "2023-12-31 23:59:59" | date, time, datetime, year, timestamp… | Некоторые форматы поддерживают часовые пояса |
| Логический (булевый) | true | bool, boolean… | Часто заменяется целыми числами 0 и 1 |
Различные базы данных поддерживают и более сложные типы, например:
- для хранения файлового содержимого (binary, blob);
- для денежных значений (money);
- для координат (point);
- для массивов (set, array);
- выбор из доступных вариантов (enum).
За детальными разъяснениями лучше всего обращаться в официальные руководства, например:
- Microsoft: https://learn.microsoft.com/…
- MySQL: https://dev.mysql.com/…
- Oracle: https://docs.oracle.com/…
- PostgreSQL: https://www.postgresql.org/…
При информационном моделировании объектов капитального строительства согласно стандарту IFC используются типы:
- Текст (IfcLabel, 255 симв.);
- Строковый (IfcText);
- Целый (IfcInteger);
- Вещественный (IfcReal);
- Булевый (IfcBoolean, true/false);
- Логический (IfcLogical, true/false/undefined);
- Дата (IfcDate).
- XML
Расширяемый язык разметки текста, используемый для хранения и передачи структурированных данных. В том числе применяется для формирования практически всех электронных документов в сфере учета недвижимости и регистрации права.
Язык разметки — это набор ключевых слов, вставляемых в текст для передачи информации о его строении. Структурированный таким образом текстовый документ содержит помимо текста мета-информацию о его составляющих.
Одним из первых языков разметки был SGML, предназначавшийся для машинной обработки документов в правительственных проектах США. На его основе позже были созданы языки HTML и XML.
Язык HTML сегодня используется как основа для построения веб-страниц. Он завоевал свою популярность благодаря простоте — в первой версии было всего 18 тегов. Современная версия, которая называется HTML5, поддерживает разнообразные интерактивные и мультимедиа-технологии.
В отличие от HTML, теги XML не предопределены. XML разрешает создавать любые теги, какие необходимы разработчику, поэтому он и называется «расширяемый» (eXtensible Markup Language).
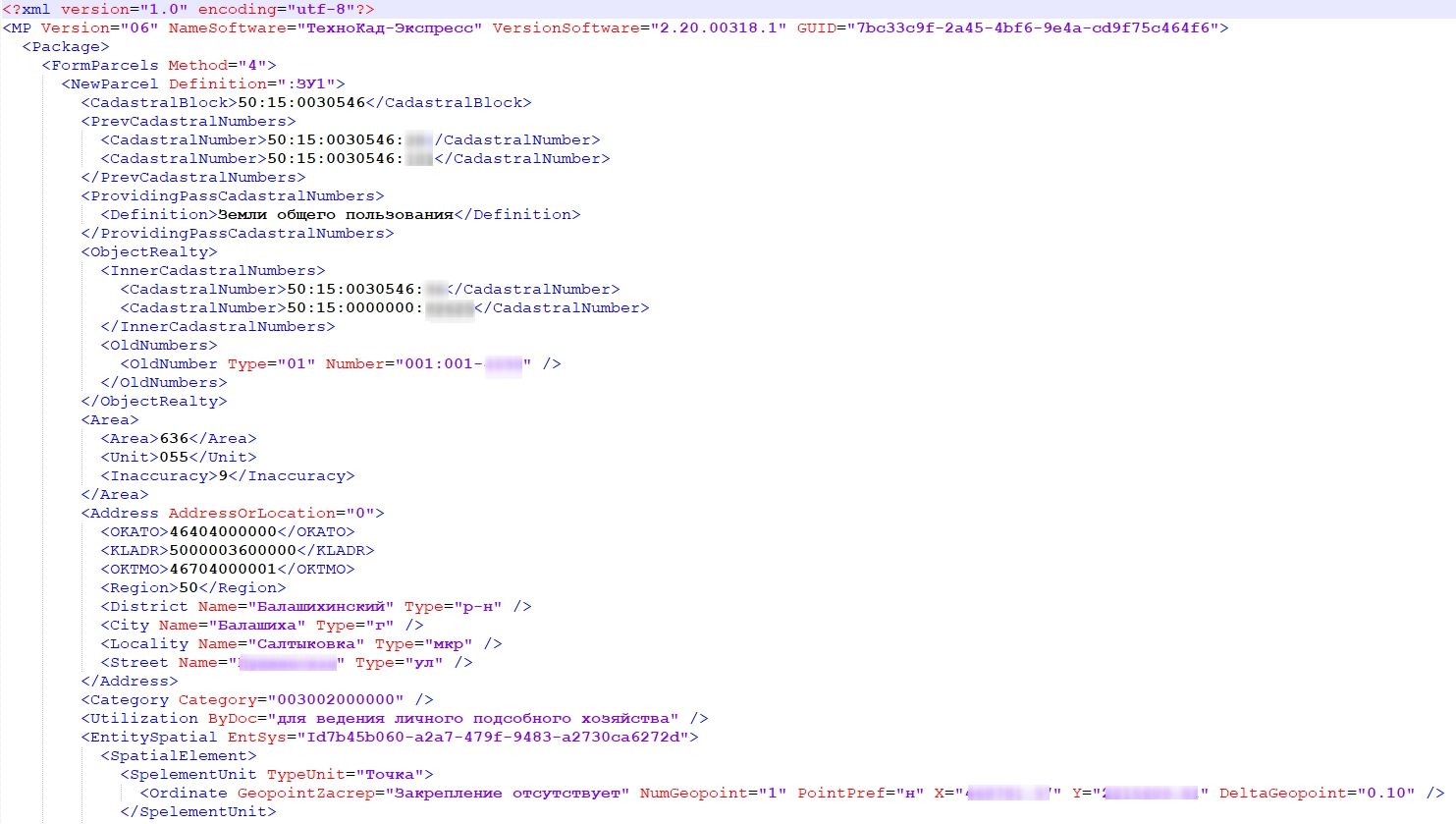
Рассмотрим пример xml-документа (см. рисунок). Первая строка — это XML декларация (пролог). Здесь определяется версия XML (1.0). Он необязателен, но если он есть, то это должна быть первая строка XML документа. На следующей строке описывается корневой элемент документа: <MP>. Следующие строки описывают дочерние элементы корневого элемента. И, наконец, последняя строка определяет конец корневого элемента: </MP>.
В XML документе могут присутствовать международные символы, вроде русских букв, и чтобы не возникало ошибок необходимо указать кодировку, либо сохранить XML файл в формате UTF-8 — это кодировка XML документов по-умолчанию.
XML документ должен содержать корневой элемент. Этот элемент является родительским для всех других элементов. Таким образом все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы). Для описания взаимоотношений между элементами обычно используют термины «родитель» (parent), «потомок» и «брат/сестра». У родительского элемента есть потомки или дочерние элементы (child). Потомки на одном и том же уровне называются братья или сестры (siblings).
В отличие от HTML, где некоторые теги могут быть одинарными (<br> — перевод строки, <img> — рисунок), в XML нельзя опускать закрывающий тег. Но при написании элементов без контента можно использовать альтернативный краткий синтаксис: вместо <OldNumber></OldNumber> можно написать <OldNumber />
XML элементы должны следовать следующим правилам написания имен:
- имена могут содержать буквы, числа и другие символы;
- имена не могут начинаться с цифры или символа пунктуации;
- имена не могут начинаться с сочетания «xml» (или XML, или Xml и т.п.);
- имена не могут содержать пробельные символы.
Рекомендуется не использовать в названиях нелатинские символы, а также . — : и спецсимволы.
Теги XML являются регистрозависимыми. Так, тег <NewParcel> не то же самое, что тег <newparcel>.
В XML все элементы обязаны соблюдать корректную вложенность, то есть нельзя написать: <Area><Unit></Area></Unit>.
Каждый элемент может содержать:
- другие элементы;
- текст;
- атрибуты.
Атрибуты часто предоставляют дополнительную информацию, которая может быть важна при обработки данных:
<SpelementUnit TypeUnit="Точка">
Значения атрибутов должны заключаться в одинарные или двойные кавычки. Если значение атрибута само содержит двойные кавычки, то можно использовать одинарные кавычки либо использовать специальные символы сущностей (мнемоники). В отличие от вложенных элементов атрибуты не могут содержать множественные значения и древовидные структуры.
В XML имена элементов определяет разработчик. Чтобы избежать конфликты имен, используются префиксы имени элемента:
<html:table>Таблица</h:table>
<furniture:table>Стол</f:table>
Пространство имен определяется в виде xmlns:префикс="URI" в атрибуте xmlns в начальном теге элемента либо в корневом элементе XML документа:
<root xmlns:html="http://www.w3.org/TR/html4/" xmlns:furniture="http://www.w3schools.com/furniture">
Итак, валидный XML документ:
- должен быть синтаксически верным:
- XML документ должен иметь корневой элемент;
- XML элемент должен иметь закрывающий тег;
- XML теги регистрозависимы;
- XML элементы должны соблюдать последовательность вложенности;
- значения XML атрибутов должны заключаться в кавычки;
- должен соответствовать определенному типу документов.
Правила, определяющие допустимые элементы и атрибуты для XML документа описываются с помощью:
- определения типа документа (DTD) (устаревающая технология);
- XML-схемы (современная технология).
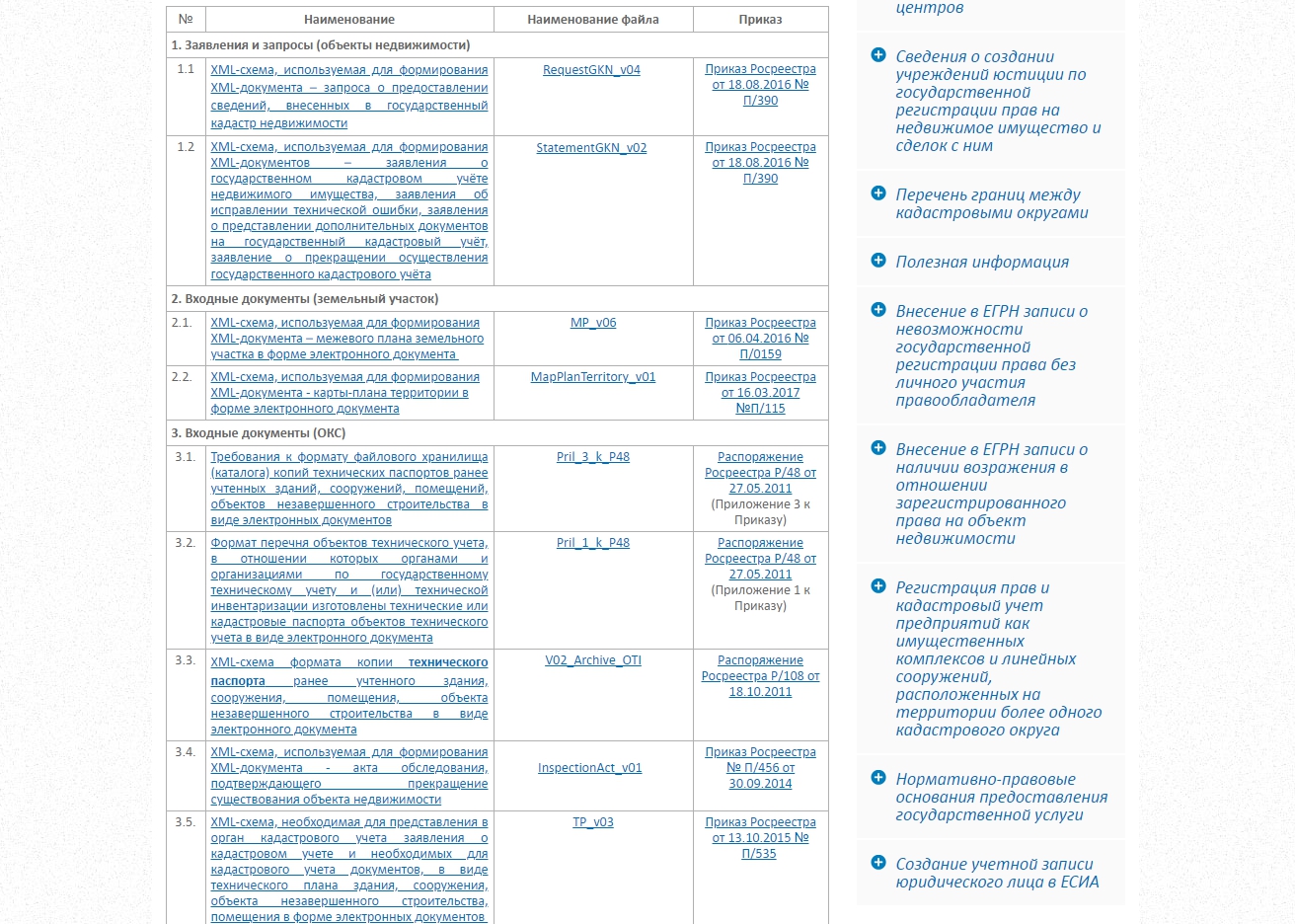
Раздел официального сайта Росреестра, на котором размещены XML-схемы, используемые для формирования XML-документов: https://rosreestr.gov.ru/activity/okazanie-gosudarstvennykh-uslug/vedenie-egrn/xml-skhemy/
Ранее помимо действующих схем заявлений, выписок и кадастровых документов на сайте выложены и проекты новых схем. Для каждого документа можно скачать архив с текстовым описанием и схемой в виде XSD файла документа и отдельных XSD с сложными элементами и классификаторами.
Также в соответствии с планом мероприятий по ускоренному внедрению онлайн-технологий в финансовый сектор Росреестр ведет работу по переводу форм договоров в XML-формат.
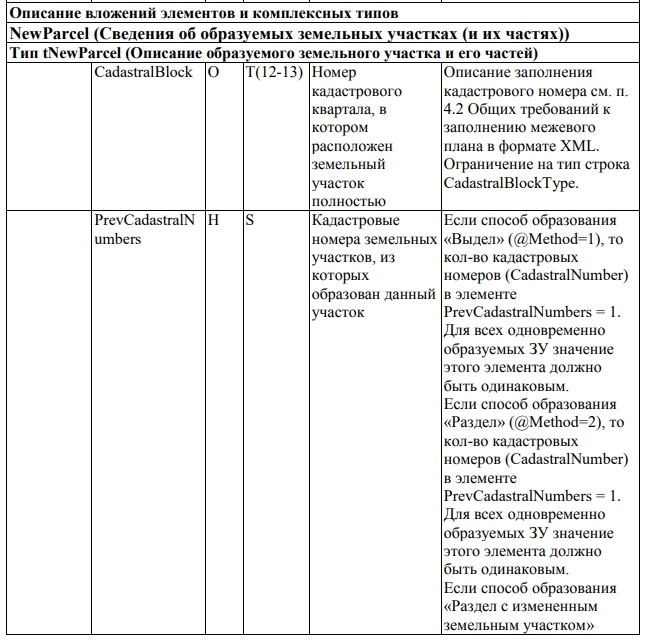
Рассмотрим для примера схему, предназначенную для формирования межевого плана. В соответствии с ней XML-файл должен представляться в кодировке Unicode (UTF-8) и иметь имя вида GKUZU_*.xml.
Документ состоит из набора файлов, упакованных в один ZIP-архив (пакет). Один документ соответствует одному пакету. Имя пакета должно иметь вид GKUZU_*.zip, где
- GKUZU — префикс, обозначающий тип документа;
- * — уникальный набор символов, соответствующий GUID, указанный в XML-файле (MP/@GUID).
В пакет должен всегда входить XML-файл (в корневом каталоге), содержащий семантические сведения документа, а также один или несколько файлов (можно в подкаталогах) с расширением PDF, XML, ZIP (графические разделы, документы Приложения):
- документы приложения, подготовленные на бумажном носителе, оформляются в форме электронных образов бумажных документов в виде файлов в формате PDF;
- документы приложения, подготовленные в форме электронного документа, оформляются в виде файлов в формате XML;
- архивы документов приложения оформляются в формате ZIP.
XML-файл документа, файлы графических разделов межевого плана и документов приложения должны быть подписаны усиленной квалифицированной электронной подписью. Файл электронной подписи должен размещаться в том же каталоге, что и подписываемый файл. Имя файла электронной подписи должно иметь вид <имя подписываемого файла>.sig
В случае, если документ приложения подготовлен в виде архива документа (ZIP-файл), файл электронной подписи должен размещаться внутри этого архива документа. Сам архив (ZIP-файл) не удостоверяется.
Описание структуры XML-схемы файла в описывающем документе приводится в табличной форме для каждого элемента или атрибута:
- код;
- содержание элемента (коды входящих элементов или атрибутов);
- тип (обязательный или необязательный, один из, множественность);
- формат (текст, число, дата, код по классификатору, булево значение истина/ложь, целое неотрицательное число, дробное число);
- наименование;
- дополнительная информация.
Стоит заметить, что некоторые сведения, предусмотренные нормативными правовыми актами, но отсутствующие в соответствующих элементах актуальных XML-схем, указываются в разделе «Заключение кадастрового инженера» кадастрового документа, например:
- информация о договоре на выполнение кадастровых работ;
- именование саморегулируемой организации, членом которой является кадастровый инженер.
XML документы не содержат в себе информации о том, каким образом следует отображать данные визуально. Браузер не понимает, что скрывается за тегом <table> — таблица или обеденный стол. Тем не менее, необходимый внешний вид документу можно придать:
- с помощью CSS (Cascading Style Sheets, каскадные таблицы стилей);
- с помощью парсера (своя программа, распознающая теги и генерирующая на их основе некий документ);
- с помощью XSLT-преобразования.
Примечание — О нумерации версий XML-схем
Кадастровые инженеры с помощью специализированного программного обеспечения формируют электронные документы в виде XML-файлов. Требования к их структуре задаются тоже в виде XML-документов, но особенных, сформированных на языке XML-схем (Schema). Такая стандартизация обеспечивает возможность автоматизации импорта данных из документации и их проверки
При актуализации нормативно-правовых актов должны обновляться схемы — для этого принято выпускать их новую номерную версию. В свою очередь изменение схем, очевидно, влечет необходимость обновления программного обеспечения, и здесь возникают интересные нюансы.
Во-первых, не всегда сами схемы полностью реализуют НПА. В этих случаях некоторые характеристики объектов недвижимости невозможно корректно описать по действующей схеме. В таких случаях приходится либо вписывать что-то близкое («нежилое здание» вместо «садовый дом»), либо указывать пояснения в непредназначенных для этого полях («садовый дом» в поле «наименование»), либо описывать ситуацию в заключении в простом текстовом виде. Все это, конечно, не способствует повышению качества данных ЕГРН.
Во-вторых, не всегда программное обеспечение способно работать с данными по актуальной схеме. Например, ФГИС ЕГРН так и не научилась считывать межевые планы, оформленные по схеме версии 9, утвержденной Приказом Росреестра №П/0341 от 16.09.2022.
В 2023 году Росреестр утвердил новые XML-схемы межевого, технического плана, акта обследования, и они привнесли новую путаницу. Дело в том, что ими утверждены вроде как обновленные схемы, но под теми же номерами версий. И только через несколько месяцев появилось обозначение вида «MP_v09_R02», где R02 — версия релиза.
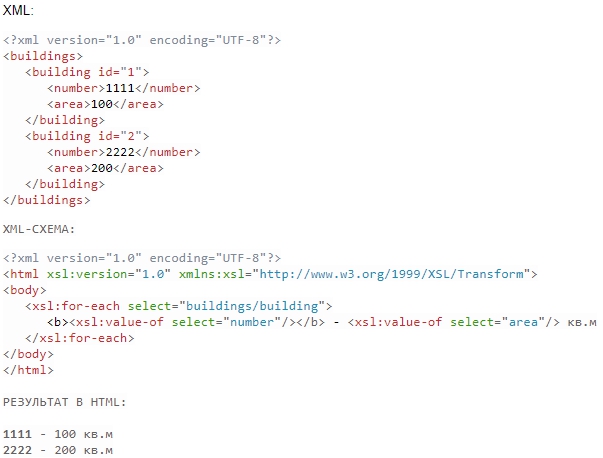
XSLT — это XML язык, который может использоваться для преобразования документов XML в другие форматы, например, HTML. К XML-документу применяются таблицы стилей XSLT, состоящие из набора шаблонов. Правила выбора и преобразования данных из XML пишутся на языке запросов XPath. В простейшем случае XSLT-процессор получает на входе два документа — входной XML-документ и таблицу стилей XSLT — и создаёт на их основе выходной документ.
- XPath
Язык, используемый:
- для поиска информации внутри XML документа;
- для определения частей XML документа;
- для навигации по XML документам.
В языке используются маршрутные выражения, похожие на путь к файлу, где вместо вложенных папок вложенные теги, например:
/ buildings / building [ 1 ] - найти первое здание.

- JSON (JavaScript Object Notation)
Текстовый формат обмена данными в виде одной из двух структур:
- объект «{"ключ": значение, "ключ": значение…}»;
- массив «[значение, значение…]».
В качестве значений могут быть использованы:
- {объект};
- [массив];
- "строка";
- число;
- true;
- false;
- null.
Спецификация: RFC 8259.

Как и для XML существует возможность описывать структуру JSON-документа с помощью JSON Schema.
Спецификация: https://json-schema.org/specification
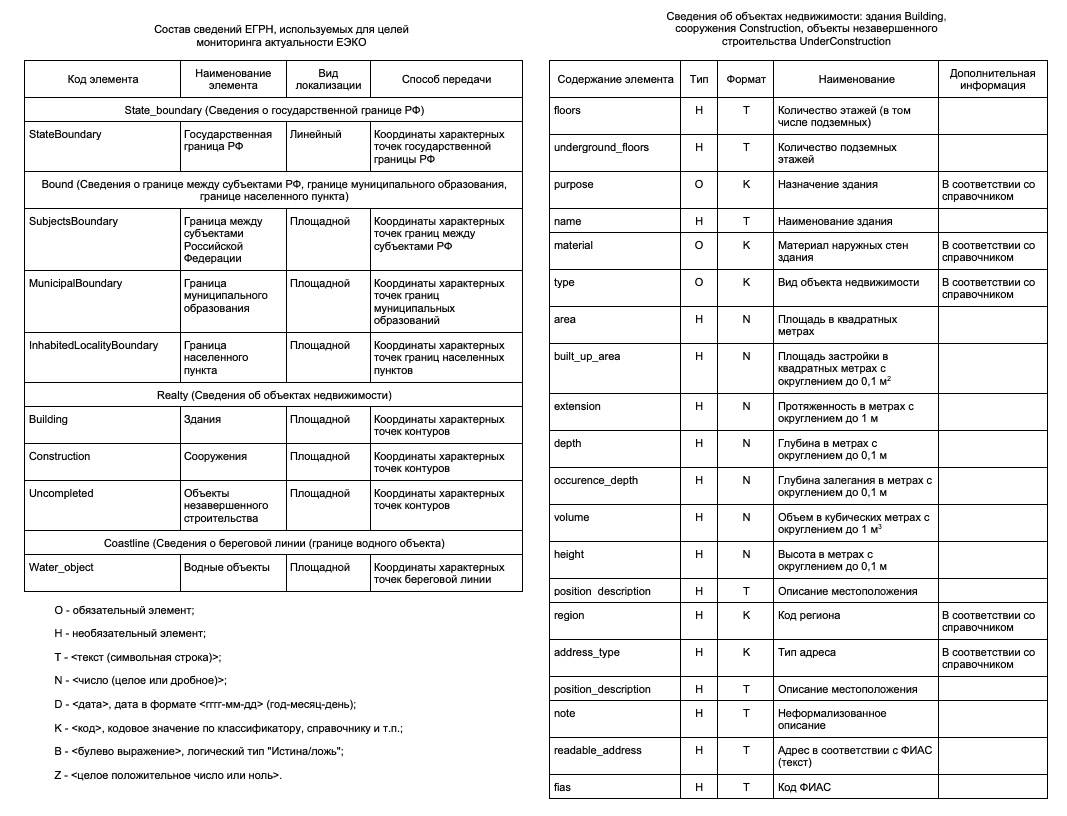
В качестве примера утвержденной JSON-схемы можно рассмотреть ГОСТ Р 70318-2022 «Национальный стандарт Российской Федерации. Инфраструктура пространственных данных. Единая электронная картографическая основа. Общие требования», согласно которому сведения ЕГРН, передаваемые в рамках информационного взаимодействия для целей мониторинга актуальности ЕЭКО, должны быть представлены в формате JSON.
По стандарту составные части JSON-файла это элементы, представляющие собой некоторую законченную смысловую единицу. Элементы могут быть:
- сложные (составные) — содержащие один или несколько вложенных элементов и, при необходимости, атрибуты;
- простые — не содержащие в себе другие элементы/атрибуты.
Одним из самых распространенных форматов, то есть наборов требований к структуре JSON файла является GeoJSON.

- GeoJSON
Формат для кодирования различных структур географических данных.
Поддерживает типы геометрии Point, LineString, Polygon, MultiPoint, MultiLineString, и MultiPolygon. Геометрические объекты с их дополнительными свойствами именуются Feature. Наборы Feature содержатся в FeatureFeatureCollection.
Спецификация: RFC 7946.
Концепция GeoJSON расширена в формате TopoJSON, в которос географические объекты представлены наборами дуг (arcs) — последовательностями точек. Экономия в размере файлов при этом достигается за счет возможности использования одной дуги в нескольких объектах.
- Реляционная база данных (relational database)
База данных, данные в которой организованы по реляционной модели.
Видов баз данных много. В реляционных информация хранится в таблицах, где каждая строка — это информация о некоем объекте или событии, а строки — их отдельные характеристики, которые еще называют атрибутами или полями.
Реляционной, то есть основанной на «отношениях», базу данных можно назвать по двум причинам:
- сведения в разных таблицах как-то соотносятся друг с другом, например, помещения находятся в зданиях;
- сведения об одном объекте или событии, если рассуждать немного филосовски, это отношение идентификатора, характеристик и их значений.
- Система управления базами данных (СУБД)
Программное обеспечение, позволяющее создавать, администрировать базы данных и выполнять все или некоторые операции с данными, которые принято разделять на четыре вида:
- создание (Create);
- чтение (Read);
- изменение (Update);
- удаление (Delete).
Тест №1
По подпискеПредварительное проектирование обязательно нужно в следующих ситуациях:
- когда вы только учитесь работать с базами данных;
- когда вы приступаете к разработке информационной системы, общее назначение и структура которой ясны, и вам нужно до начала работ согласовать все детали, чтобы минимизировать работу по переделке в будущем.
Перед проектированием следует установить алгоритм выполняемой задачи, участников действий. Для этого стоит составлять диаграммы и блок-схемы, например в нотации BPMN или UML.
- Блок-схема (flowchart, flow diagram)
Графическое представление задачи для проведения анализа или решения с помощью специальных символов, обозначающих такие элементы как операции, данные, поток или технические средства.
Таблица — Основные элементы блок-схемы
| Обозначение | Описание |
|---|---|
| Круг или прямоугольник с сильно скругленными углами | Терминаторы — точки входа и выхода, начала и окончания алгоритма |
| Прямоугольник с текстом внутри | Действие, операция |
| Стрелка | Переход к следующему действию |
| Ромб с текстом | Развилка, условие |
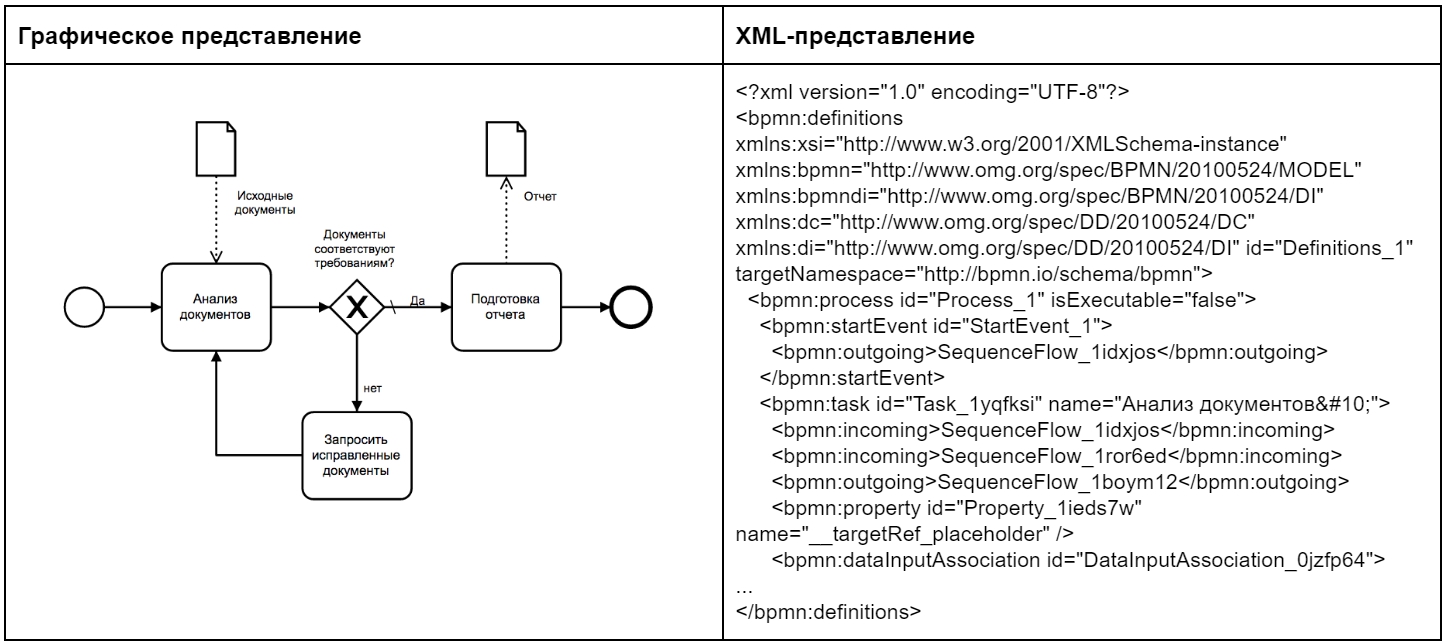
Более современным общемировым стандартом описания алгоритмов процессов является Business Process Model and Notation (BPMN) — нотация и модель бизнес-процессов. Это система условных обозначений (нотация) для моделирования бизнес-процессов.
Базовые условные обозначения здесь всё те же, отдельно можно обратить внимание на условное обозначение документа или данных в виде листа бумаги. Процессы описываются на языке XML по стандартизированной схеме. Таким образом обеспечивается чтение файлов в различном программном обеспечении.
Ресурсы по BPMN:
- официальный сайт с образцами http://www.bpmn.org/
- спецификация формата http://www.omg.org/spec/BPMN/2.0/
- подсказки по условным обозначениям http://www.bpmb.de/images/BPMN2_0_Poster_RU.pdf
- онлайн-редактор https://bpmn.io
В подсказках по условным обозначениям обратите внимание на подвиды отдельных элементов, например на то, что логические операторы могут быть параллельными и исключающими.
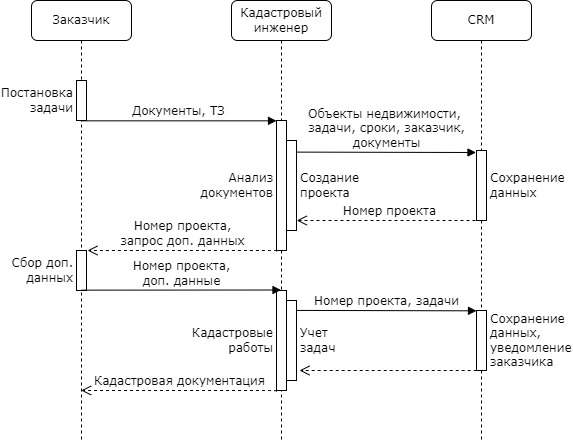
Наиболее распространенная, более широкая нотация, используемая при составлении различных схем, это UML (Unified Modeling Language, унифицированный язык моделирования) — язык графического описания для объектного моделирования в области разработки программного обеспечения, моделирования бизнес-процессов, системного проектирования и отображения организационных структур.
С помощью UML можно составлять самые разнообразные диаграммы. К примеру, близкий аналог BPMN — это диаграмма деятельности (activity diagram), которая позволяет описывать некое поведение на основе указания потоков управления и потоков данных.
Другая удобная для формализации процессов диаграмма — это диаграмма последовательности (sequence diagram), на которой для некоторого набора объектов на единой временной оси показано их взаимодействие в виде запросов и ответов.

Используя эти диаграммы, можно наглядно представить как бизнес-процессы организации, так и происходящее внутри программного обеспечения. Можно их использовать и в обычной жизни для планирования различных работ, в которых задействовано несколько лиц.
Диаграммы последовательности можно создавать в различных графических и специализированных редакторах вроде https://draw.io или, например, в Google Документах непосредственно в текстовом редакторе. Для этого установите дополнение “WebSequenceDiagrams” и вы можете описывать последовательность работ простым текстом, по которому автоматически генерируется диаграмма.
- Модель данных (data model)
Схема структурирования данных в базе данных в соответствии с формальными описаниями в ее информационной системе и требованиями используемой системы управления базой данных.
- Реляционная модель данных (relational model)
Модель данных, структура которой основана на реляционных отношениях.
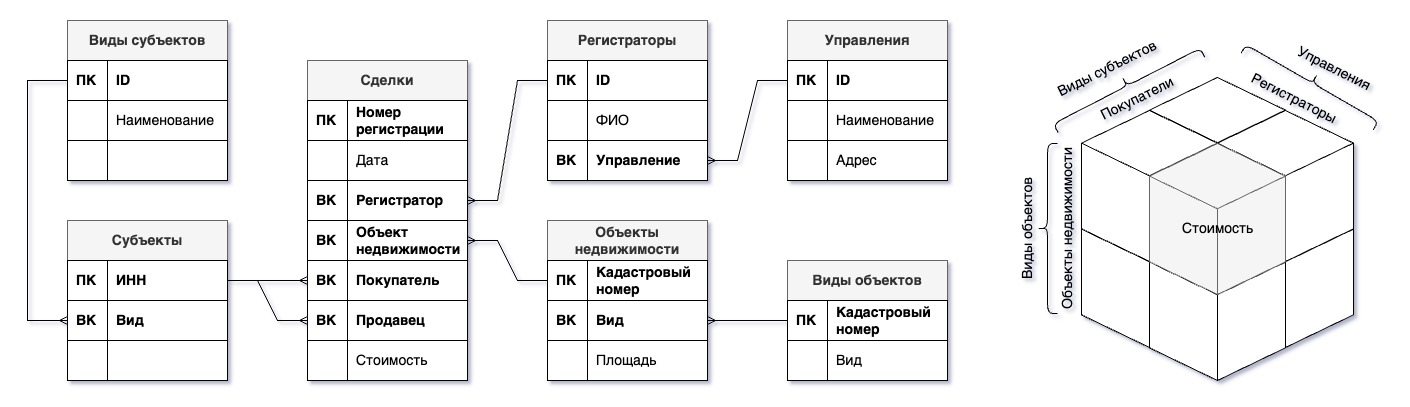
- ER-модель (Entity-Relationship model, модель «сущность — связь»)
Модель, описывающая структуру реляционной базы данных в виде учитываемых сущностей и связей между ними.
- ER-диаграмма (Entity-Relationship diagram, диаграмма «сущность — связь»)
Графическая нотация или набор условных знаков, с помощью которых достаточно удобно проектировать реляционные базы данных в рамках ER-модели. В самой простой для использования версии диаграммы всего три обозначения:
- сущности;
- атрибуты сущности;
- связи между сущностями.
- Сущность (entity)
Что угодно, что имеет смысл выделить в рассматриваемом случае, и информацию о чем удобно хранить отдельно. Обычно это понятный предмет реального мира, некий виртуальный объект или запись о некоем событии или факте.
При информационном моделировании зданий и сооружений — класс информации, определяемый общими атрибутами и ограничениями согласно ISO 10303-11. Аналог термина «класс» в обычных языках программирования, но с описанием только структуры данных без описания поведения при помощи методов.
В ER-диаграмме сущности изображают в виде прямоугольника с указанным внутри названием. Так как в таблице обычно содержатся сведения о множестве объектов, то логично называть сущности во множественном числе.
После проектирования, когда дело дойдет уже до создания непосредственно рабочей базы данных, сущности превратятся в отдельные таблицы.
- Атрибуты (поля, характеристики)
Любые свойства сущности, необходимые для решения задач, которые ставятся перед информационной системой, работающей с данной базой данных. Это может быть имя для человека, площадь для земельного участка и так далее.
При описании качества пространственных данных — (feature attribute) характеристика объекта. Имеет имя, характеризуется определенным типом данных и имеет область допустимых значений. Атрибут экземпляра объекта также имеет значение атрибута, принадлежащее области допустимых значений.

В простой ER-диаграмме названия атрибутов пишутся в столбик под именем сущности. Имена характеристикам стоит давать простые, короткие и однозначные. Не надо уточнять, про какой объект идет речь, вроде «Адрес участка» для сущности «Участки», ведь и так ясно, что это свойство участка.
Позже, в рабочей таблице атрибуты превратятся в ее колонки.
Сразу стоит отмечать, какие из атрибутов являются первичными ключами. Это можно сделать, например, указав «ПК» перед названием атрибута. Во многих СУБД первичные ключи отмечаются символом ключа.
Также имеет смысл подписывать справа от названий атрибутов форматы данных, например, int для целочисленных значений, text — для текстовых и так далее.
- Связь (relation)
Связи описывают отношения между сущностями. Принято выделять три вида:
- один-к-одному (в предложении о продаже идет речь об одном помещении);
- один-ко-многим (здание и помещения);
- многие-ко-многим (правообладатели и недвижимость).
Здесь стоит заметить, что «один-к-одному» это частный случай «один-ко-многим» и встречается редко.
В простой ER-диаграмме связи показываются линиями от одной сущности до другой или, если более точно, от внешнего ключа в одной таблицы до соответствующего первичного ключа в другой. На каждом конце линии указывают соответствующую степень — один или много. В качестве обозначения «много» рекомендуется писать «n», но в примерах можно встретить «*», «∞» или трезубец.
В рабочих таблицах эти связи реализовываются с помощью внешних ключей или промежуточных таблиц.
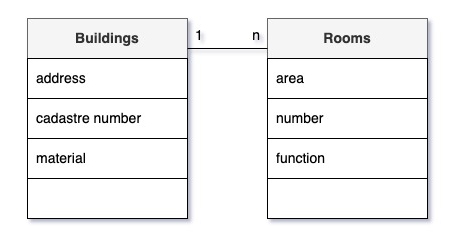
Первое время кажется сложным определить вид связи, но это очень легко сделать, задав себе вслух для каждой пары сущностей вопросы вида «С одним А сколько Б может быть связано?» и «С одним Б сколько А может быть связано?»
Например, у нас есть Здания и Помещения. Зададим вопросы:
- «С одним Зданием сколько Помещений может быть связано? Много!»
На конце связи, подходящей к Помещениям отмечаем «n». - «С одним Помещением сколько Зданий может быть связано? Одно!»
На конце связи, подходящей к Зданиям отмечаем «1».
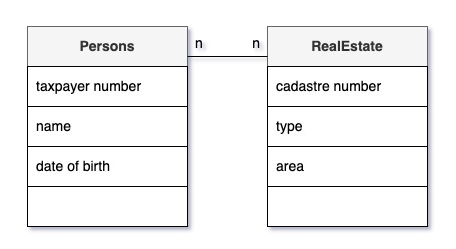
Или допустим, что у нас есть Правообладатели (Persons) и их Недвижимость (RealEstate). Зададим вопросы:
- «С одним Правообладателем сколько объектов Недвижимости может быть связано? Много!»
На конце связи, подходящей к Недвижимости отмечаем «n». - «С одним объектом Недвижимости сколько Правообладателей может быть связано? Тоже много!»
На конце связи, подходящей к Правообладателям отмечаем «n».
Тест №2
По подпискеДля начала стоит доработать диаграмму, чтобы убедиться, что все готово для создания таблиц в точности по ней:
- расставить первичные и внешние ключи;
- избавиться от типичных ошибок проектирования путем нормализации.
- Первичный ключ (primary key)
В информационных технологиях — ключ порции данных, значения которого однозначно идентифицируют порции данных в заданной их совокупности.
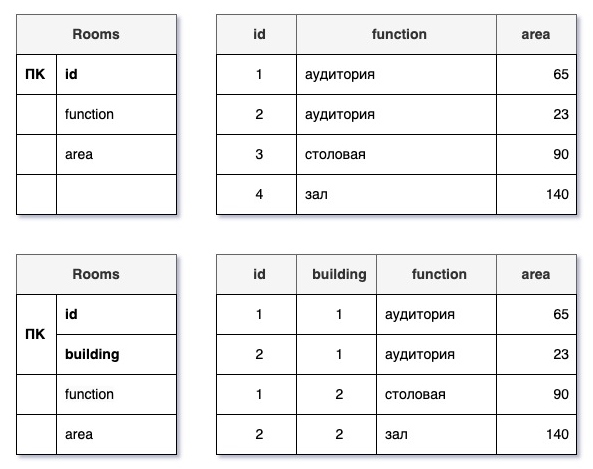
Можно сказать, что это уникальный идентификатор каждой строки в таблице. В большинстве случаев можно просто в каждую таблицу добавить (обычно первым) атрибут с общепринятым именем «ID» и типом int — целочисленный. Это будет просто номер строки в порядке добавления.
Тем не менее, никто не запрещает называть первичные ключи, да и любые другие атрибуты, как угодно иначе. Более того, первичные ключи могут быть составными, например для помещения это могут быть два атрибута: «Здание» и «Номер». По-отдельности они не уникальны, но их совокупность будет однозначно идентифицировать каждую строку.
- Внешний ключ (вторичный ключ, foreign key)
В информационных технологиях — ключ порции данных, значения которого могут быть одинаковыми для нескольких порций данных в заданной их совокупности.
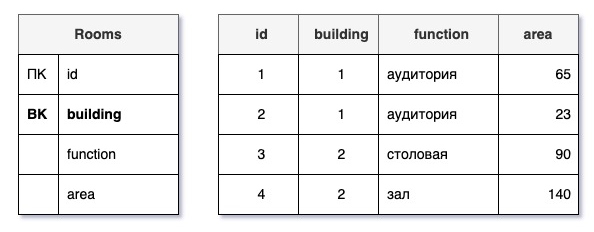
Говоря проще, это атрибут сущности, по сути являющийся ссылкой на другую сущность. Например, в таблице «Помещения» логично создать ссылку на здание, в котором находится каждое помещение.
Именовать внешние ключи лучше так, как называется другая соответствующая (внешняя) таблица, но в единственном числе, например, «здание». Нет нужды писать что-то вроде «ID здания», так как это несколько визуально «захламляет» структуру базы данных. Keep it simple.
Когда мы будем описывать конкретное помещение, мы не будем писать адрес здания или другую его характеристику, чтобы понять о каком объекте капитального строительства идет речь. Вместо этого мы во внешнем ключе с именем «здание» в таблице «Помещения» просто напишем идентификатор нужного здания (грубо говоря — номер строки).
С расстановкой внешних ключей ситуация сложнее. На время обучения рекомендуется следующий «автоматический» способ, который позволит вам решить эту задачу верно, хоть и неосознанно. В дальнейшем, по мере накопления опыта, это уже не понадобится.
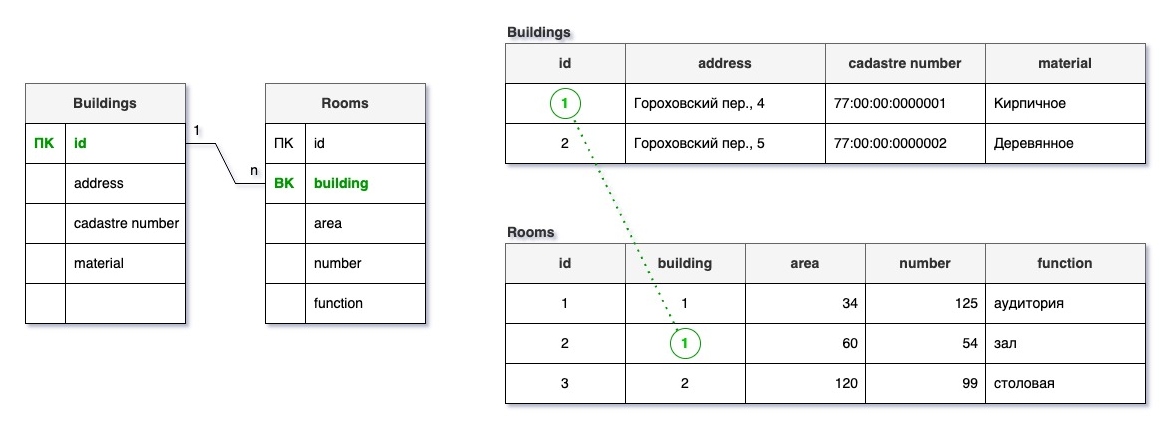
Если связь «один-ко-многим»:
- в таблице, где «один» создайте первичный ключ, если его нет;
- в таблице, где «много» создайте внешний ключ и назовите его так, как называется другая таблица в единственном числе.
В дальнейшем, когда у нас будут созданы таблицы, значениями внешнего ключа станут соответствующения значения первичного. В примере с зданиями и помещениями это id нужного здания.

Типичной ошибкой здесь будет попытаться в поле внешнего ключа внести не соответствующие первичные ключи, а какую-нибудь другую характеристику, например, фамилию или адрес.
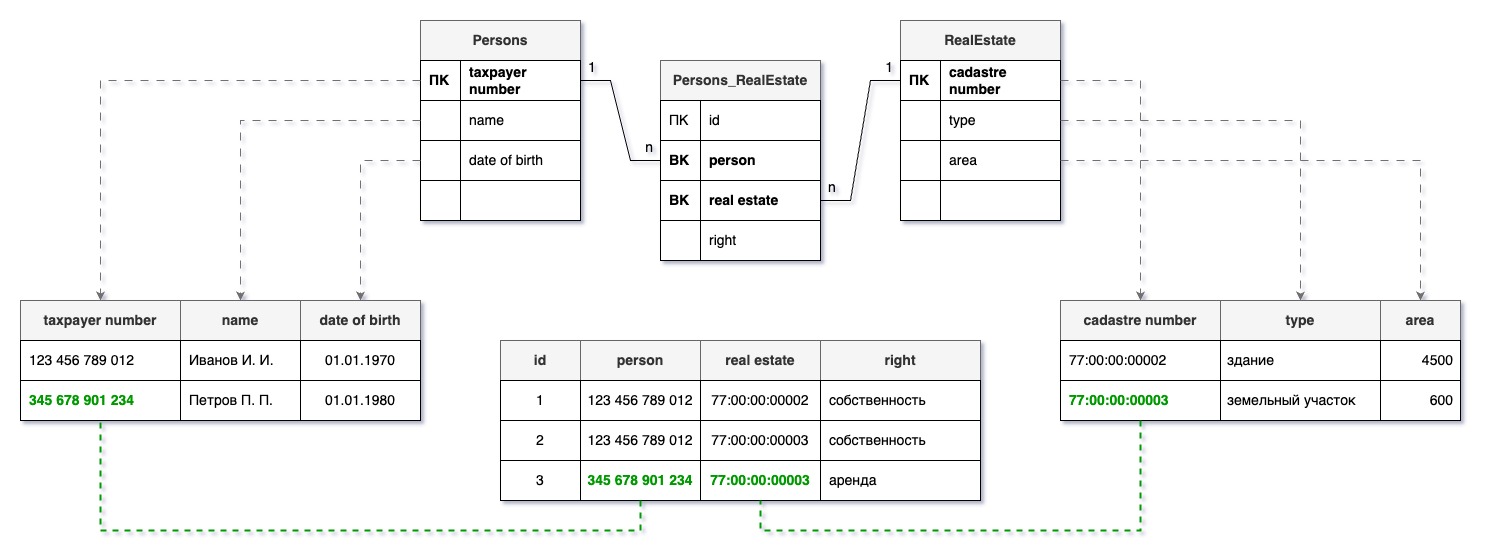
Если связь «многие-ко-многим»:
- в обоих таблицах создайте первичные ключи, если их нет;
- создайте промежуточную таблицу со своим первичным и двумя внешними ключами, соответствующими первичным ключам связанных таблиц. Назовите внешние ключи так, как называются другие соответствующие таблицы в единственном числе;
- при необходимости в промежуточную таблицу можно добавить и другие атрибуты, которые описывают эту связь. В примере это поле right, в котором содержится описание права персоны на недвижимость.
Например, в данном случае Петров арендует у участок Иванова площадью 600 кв.м. Вместо простых порядковых номеров используем уникальные кадастровые номера и ИНН.

Здесь также необходимо следить за соответствием внешнего и первичного ключей. Не стоит вместо точно уникального идентификатора правообладателя использовать, например, его ФИО.
Последовательное улучшение структуры базы данных в целях избавления от дублирования данных и общей несогласованности называется нормализацией.
По мере выполнения проверок считается, что база данных находится в той или иной нормальной форме:
- первая форма:
- в одной ячейке нет нескольких внешних ключей;
- расположение строк не имеет значения;
- расположение колонок не имеет значения;
- определен первичный ключ;
- вторая форма:
- нет атрибута, который бы являлся на самом деле характеристикой другой сущности, на которую стоит ссылка в составном первичном ключе, например:
[Номер здания] [Номер помещения] Назначение помещения Назначение здания
- нет атрибута, который бы являлся на самом деле характеристикой другой сущности, на которую стоит ссылка в составном первичном ключе, например:
- третья форма:
- нет атрибута, который бы являлся на самом деле характеристикой другой сущности, например:
[Номер помещения] Назначение помещения Площадь Минимальная площадь
- нет атрибута, который бы являлся на самом деле характеристикой другой сущности, например:
Есть и другие нормальные формы, но рассматриваемые в них случаи весьма нетривиальны. Первых трех достаточно в большинстве случаев.
Тест №3
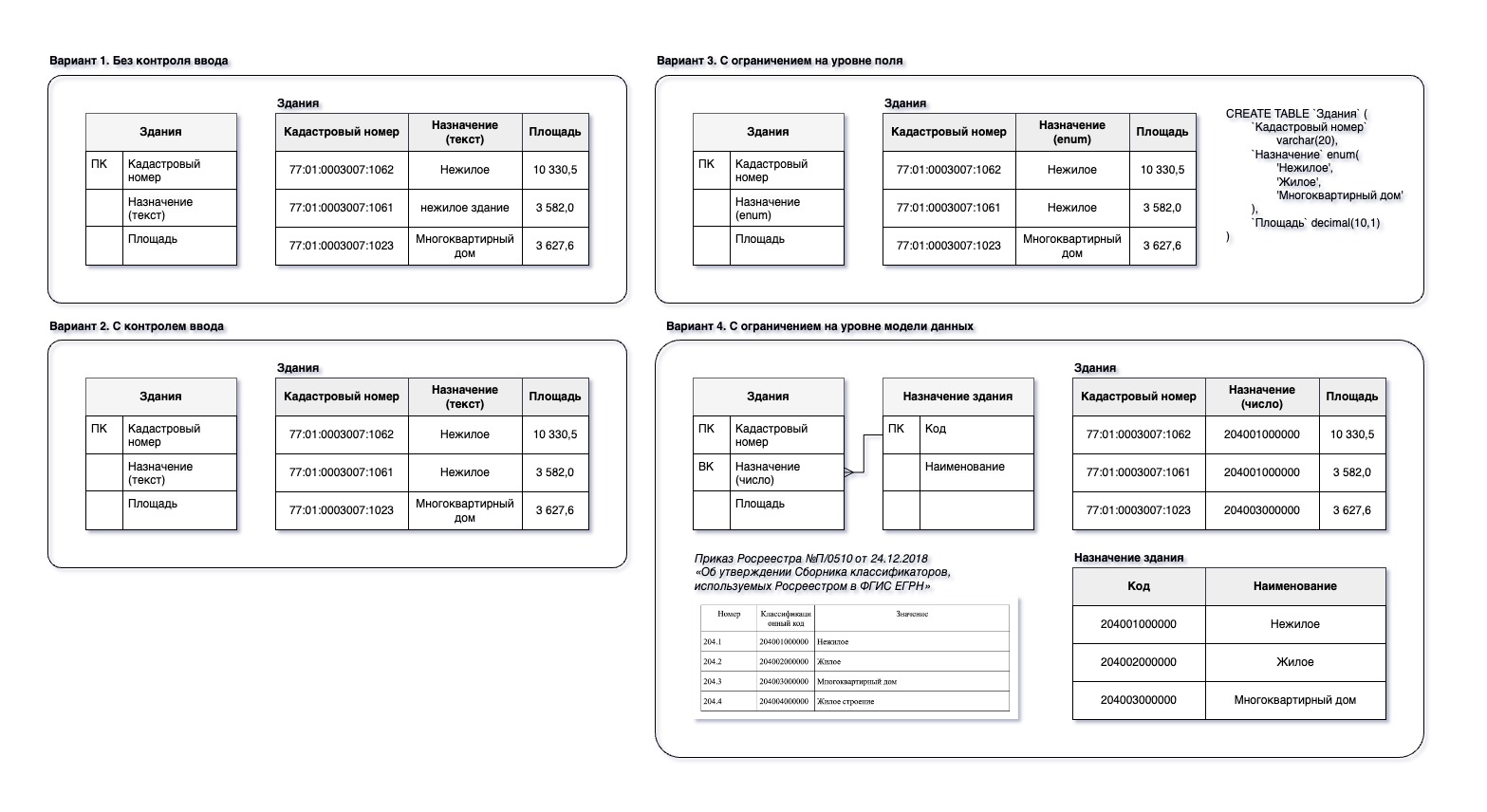
По подпискеЗачастую какая-либо характеристика может принимать только значения из определенного перечня. Очевидно, что если предоставить пользователям возможность вводить в таком случае их самостоятельно, это понизить качество данных, ведь для информационной системы, не обремененной дополнительным алогоритмическим или нейросетевым аппаратом, «Улица», «улица» и «ул.» — это разные вещи.
Мы можем ограничить пользователя разными способами:
- на этапе внесения данных выполнять проверку, отклонять или приводить значение к допустимому варианту перед сохранением в базу данных;
- на уровне настроек поля базы данных (домена) разрешить только определенные значения по списку, используя специальный тип поля, например, "enum";
- на уровне модели данных создать отдельную таблицу (классификатор), содержащую допустимые значения, и установить ограничение на соответствующий внешний ключ, например, "CONSTRAINT name FOREIGN KEY (foreign key) REFERENCES table (primary key)".
В некоторых случаях лучше создавать отдельные классификаторы, которые, кстати, можно объединить в одну таблицу. Иногда целесообразнее обойтись более простым решением. В любом случае стоит заранее продумать порядок действий, когда со временем неизбежно наступит необходимость уточнения самого применяемого классификатора.
Существует несколько «стандартных» подходов к построению реляционной базы данных. Как минимум, стоит выделить следующие:
- «классическая» ("Objects as Tables" — отдельные таблицы для каждой сущности);
- «универсальная» (общие таблицы сущностей и характеристик);
- «таблица фактов» (OLAP).
Для примера мы будем рассматривать простую ситуацию, в которой нам нужно учитывать объекты капитального строительства и земельные участки с учетом следующих условий:
- ОКС бывают различных видов (здание, сооружение);
- у них есть характеристики: простые (площадь или протяженность) и сложные (адрес);
- ОКС могут располагаться на нескольких земельных участках:
- на одном земельном участке может быть несколько ОКС.
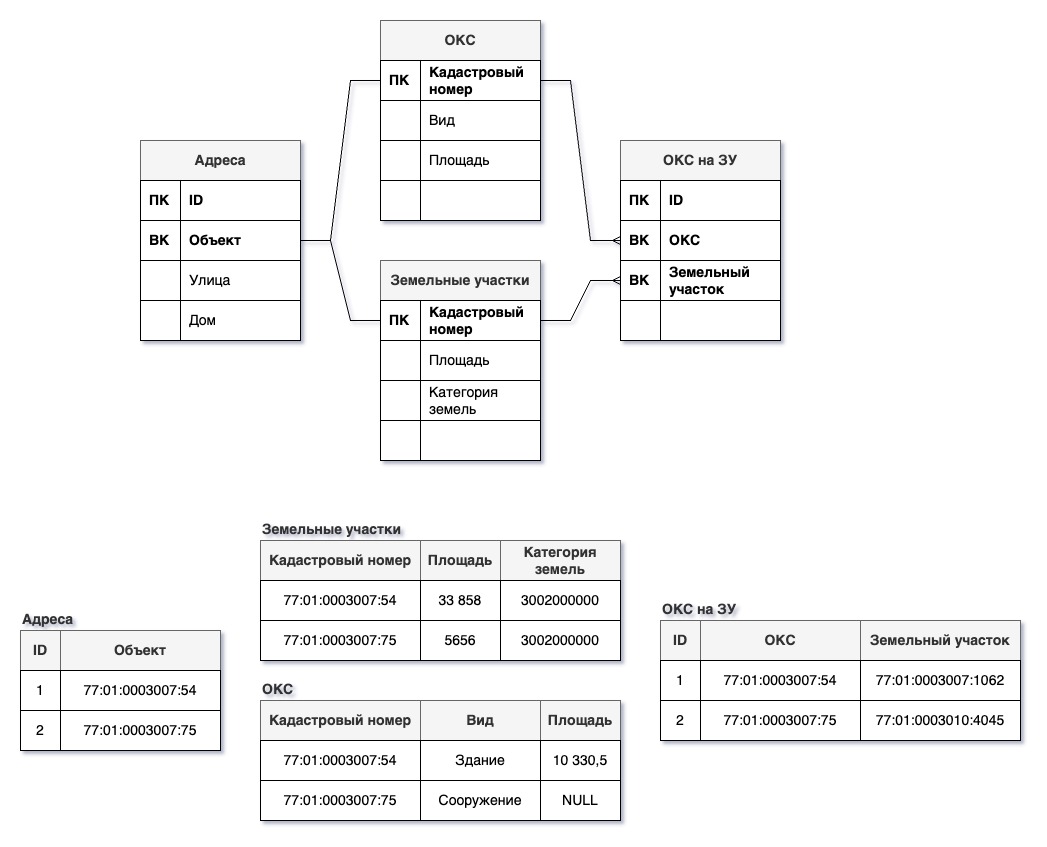
Это очень гибкая структура, которая может обернуться хаосом с ростом числа учитываемых сущностей при ненадлежащей нормализации.
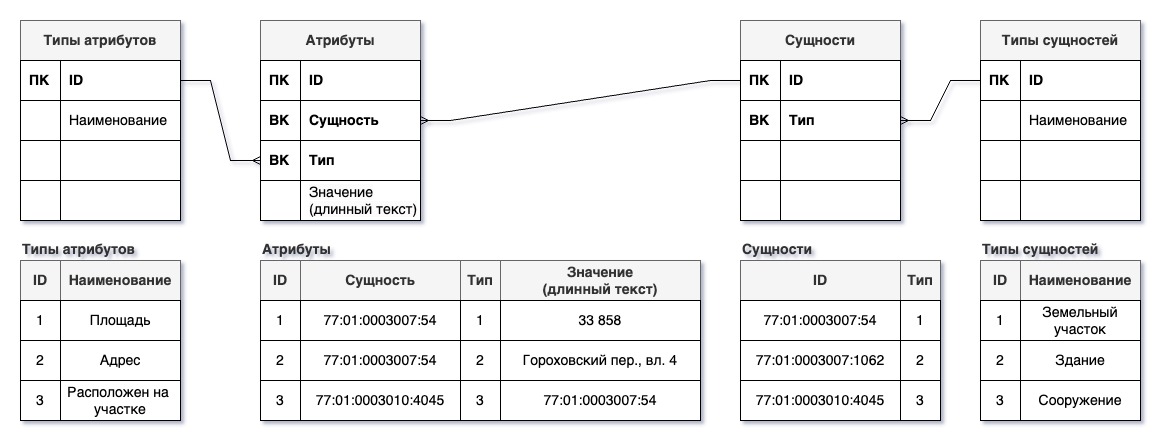
«Универсальная» схема базы данных предполагает наличие общих таблиц сущностей и их характеристик. В самом простом виде у нас будут таблицы:
- классификатор сущностей;
- список сущностей;
- классификатор характеристик;
- значения характеристик.
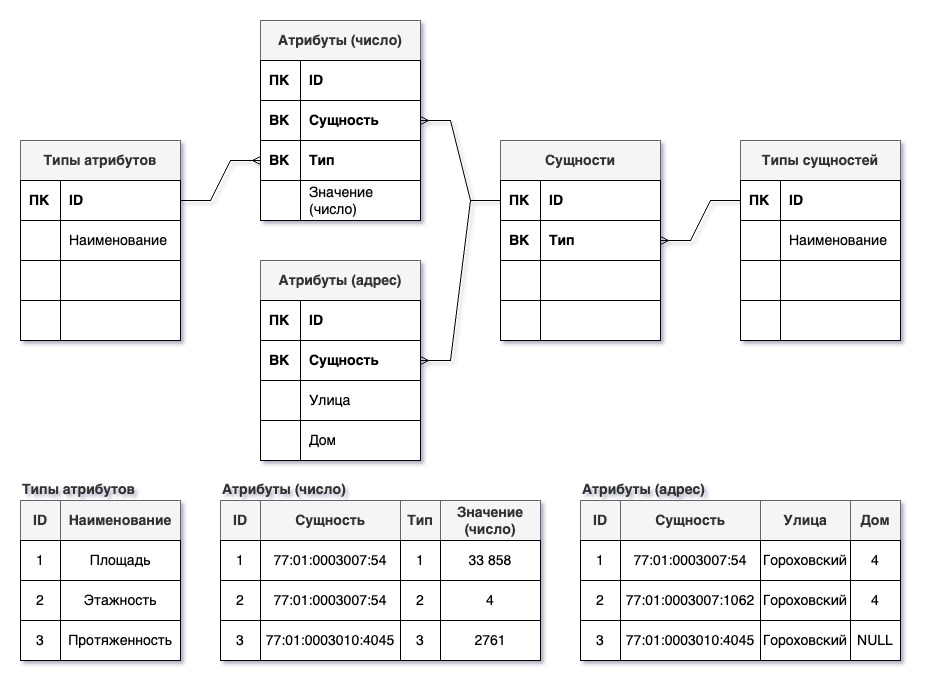
Основной трудностью при создании таких баз данных является поддержка разных типов данных. В примере выше мы вынуждены хранить значения всех характеристик как текст. Если этот вариант не устраивает, в принципе можно попытаться создать в таблице значений характеристик дополнительные поля для других типов: целое число, число с плавающей запятой, дата и так далее. Но скорее всего это будет неудобным при большом количестве возможных типов данных, особенно сложно структурированных. Поэтому создают отдельные таблицы для хранения значений характеристик разного типа. Так можно создать таблицу со множеством полей для хранений, например, элементов адреса. Стоит в отдельную таблицу вынести и внешние ключи, чтобы в целях ускорения поиска можно было создать для них индексы.
Такие «универсальные» базы используют для систем, подразумевающих создание баз данных самими пользователями под конкретную текущую задачу. Так один набор таблиц может содержать в себе сразу множество баз данных. А вот если база данных предназначена для решения задач одной системы, то применение этого подхода обернется трудностями как при проектировании, так и при создании запросов.
«Таблицы фактов» или OLAP-кубы обычно используют либо в очень простых базах данных, либо в качестве «витрин» существующих более сложных структур. Такая схема хорошо подходит для представления данных о неких событиях и плохо работает при небходимости детализации данных о множестве сущностей.
- Интерактивная аналитическая обработка (OLAP, online analytical processing)
Спобоб представления агрегированных данных в виде таблицы фактов и соответствующих таблиц измерений.
OLAP-куб — многомерный массив данных, где индексы соответствуют измерениям (dimensions), а значения — мерам (measures).
В самой простой схеме OLAP-куба, которая называется «звезда», есть центральная «таблица фактов» и вокруг нее таблицы «измерений». В таблице фактов есть «меры», характеризующие факты, например, стоимость.
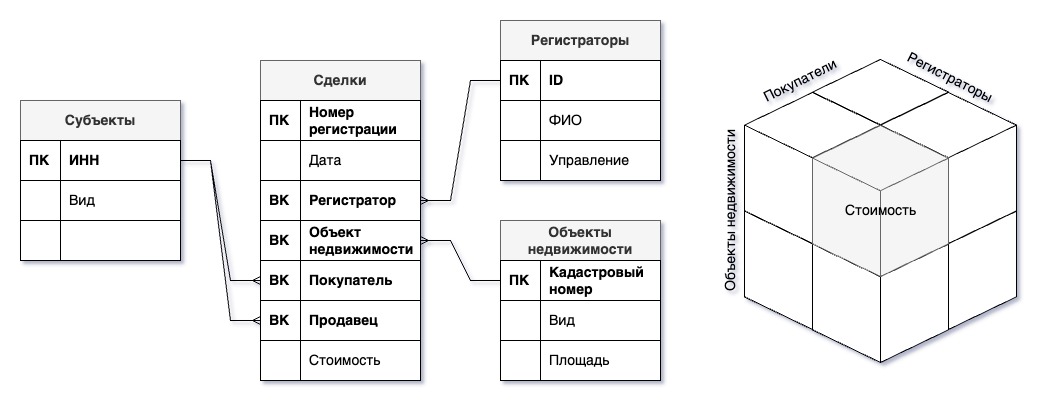
Если же мы добавляем некие группы для измерений, такая форма именуется «снежинка». В идеальной ситуации допускается только связь «многие-ко-одному». Специализированные СУБД позволяют заранее просчитать все возможные варианты агрегированных значений, например, сумму по всем сделкам с помещениями за определенный год, что значительно ускоряет анализ при большом объеме данных. В обычной реляционной СУБД такие расчеты выполняются по запросу.
Заметим, что ситуация резко осложняется при необходимости реализации связи «многие-ко-многим». Тогда применяются обходные пути, специфические для используемого программного обеспечения.
- Язык базы данных
Язык с использованием формального синтаксиса, предназначенный для определения, создания, организации доступа и поддержки базы данных.
- SQL (язык структурированных запросов, Structured Query Language)
Язык баз данных, описанный в Международном стандарте ISO/IEC (ИСО/МЭК) 9075.
Запросы на языке SQL основаны на реляционной алгебре, то есть на системе операций над отношениями в реляционной модели данных.

Проекция — это операция в реляционной алгебре, при которой из таблицы выбираются нужные столбцы, например:
-
Выбор одного столбца из таблицы
SELECT area FROM rooms; -
Выбор нескольких произвольных столбцов в одной таблице
SELECT id, area FROM rooms; -
Выбор всех столбцов в одной таблице
SELECT * FROM rooms; -
Создание псевдонимов столбцов
SELECT area AS Площадь FROM rooms; -
Удаление дубликатов строк (без удаления данных)
SELECT DISTINCT area FROM rooms; -
Выполнение сортировки по одному произвольному столбцу
SELECT area FROM rooms ORDER BY area ASC/DESC; -
Сортировка по нескольким столбцам
SELECT area FROM rooms ORDER BY building ASC/DESC, area ASC/DESC;
Выборка — это операция в реляционной алгебре, при которой из таблицы выбираются нужные строки, например:
-
Фильтрация строк с помощью произвольного сравнения
SELECT * FROM rooms WHERE area > 100;
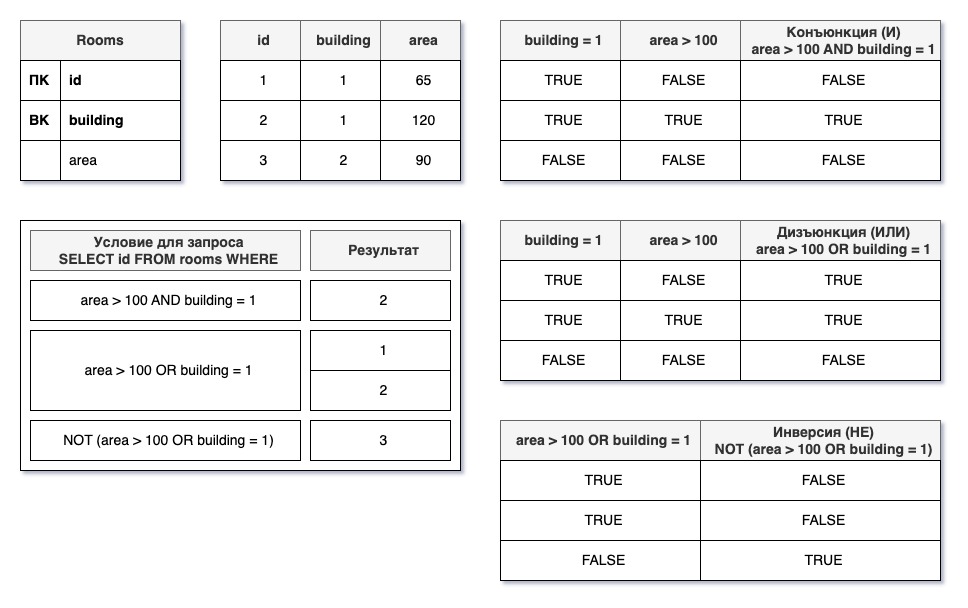
- Комбинирование условий с помощью логических операторов AND, OR и NOT
SELECT * FROM rooms WHERE area > 100 AND building = 1; -
Фильтрация строк по произвольному списку
SELECT * FROM rooms WHERE id IN (1, 4, 35);
-
Проверка на значение null с помощью оператора IS NULL / IS NOT NULL
SELECT * FROM rooms WHERE area IS NULL;
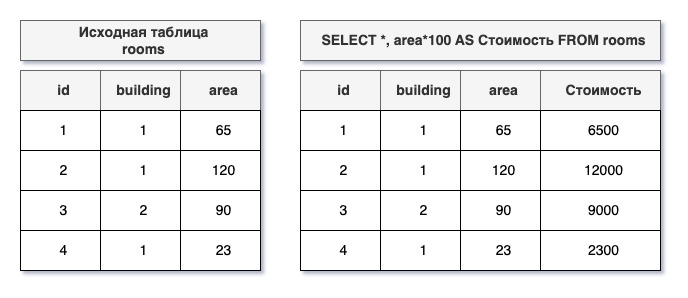
В запросе можно для каждой строки выполнять как простые, так и достаточно сложные математические операции. Принцип составления формул похож на применяемый в MS Excel, например:
- Просто калькулятор
SELECT 2+2; - Расчет с выводом результата в отдельном столбце
SELECT area*100 AS Стоимость FROM rooms; - Расчет в условии
SELECT * FROM rooms WHERE area*100 > 10000;

Для расчетов по столбцам используются агрегатные функции, например:
-
Подсчет строк
SELECT COUNT(*) FROM rooms WHERE area > 100; - Обобщенное значение
SELECT MIN/MAX/AVG(area) FROM rooms; -
Группирование строк
SELECT floor, COUNT(*) FROM rooms GROUP BY floor;
-
Фильтрация групп
SELECT floor, COUNT(*) FROM rooms GROUP BY floor HAVING COUNT(*) > 3;
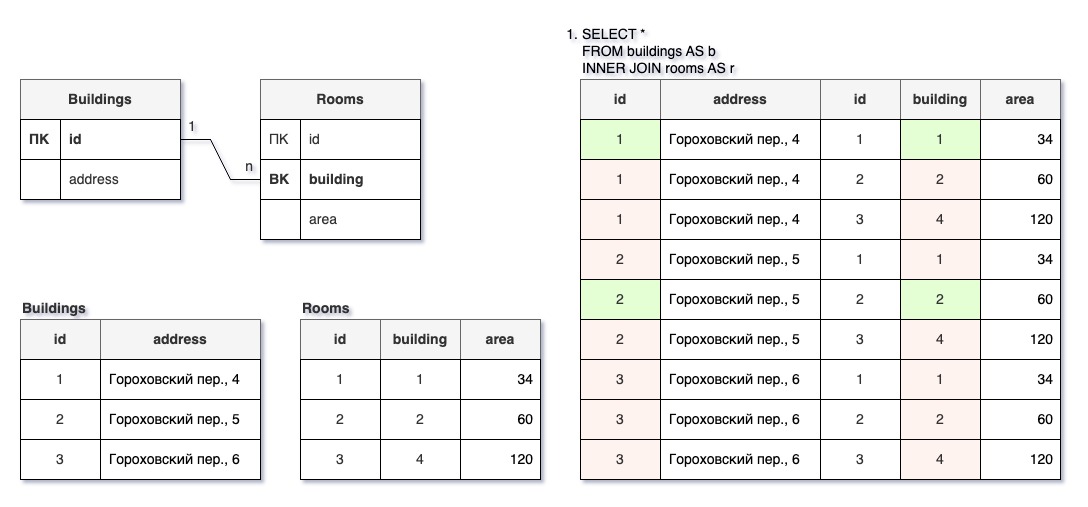
Соединение — это операция в реляционной алгебре, при которой сначала устанавливаются всевозможные сочетания строк из нужных таблиц (так называемое умножение или декартово произведение), а потом в получившейся большой таблице отбираются лишь нужные строки.
На иллюстрации просто соединены таблицы зданий и помещений. Видно, что в результате составляются все возможные комбинации строк из двух таблиц. В этом, конечно, нет практического смысла — нас интересует только строки, в которых совпадают идентификаторы здания (первичный ключ в таблице зданий и внешний ключ в таблице помещений).
Поэтому нам необходимо установить условие отбора нужных строк. Это можно сделать двумя способами:
- как обычное условие: WHERE r.building = b.id;
- с помощью ключевого слова ON r.building = b.id (рекомендуется).
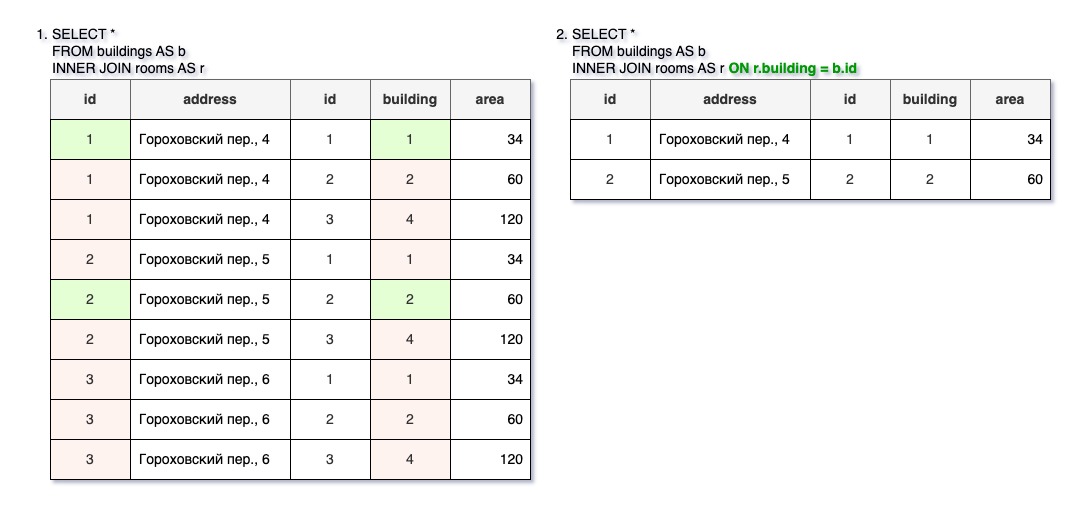
Внутреннее соединение (INNER JOIN) используется, если нужно отобрать только такие объекты, для которых есть соответствующие связанные объекты в другой таблице.
В примере, так как в здании с ID=3 нет помещений, а помещение с ID=3 расположено в неучтенном здании, то строк с этими зданием и помещением в результате запроса нет.
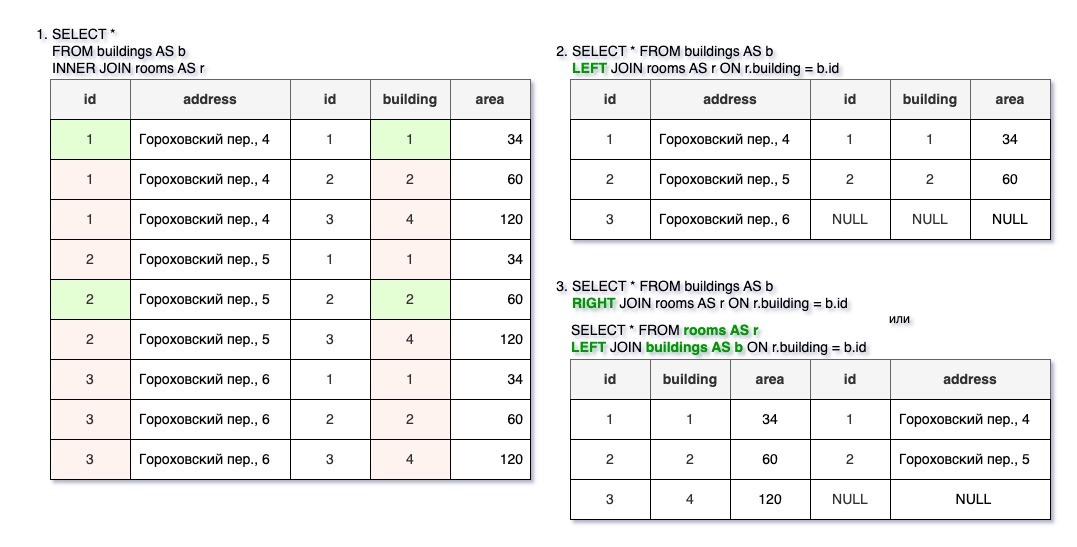
Внешнее соединение (LEFT JOIN или LEFT OUTER JOIN) используется, если нужно показать все основные объекты, независимо от того, есть ли соответствующие связанные объекты в другой таблице. Для отсутствующих значений отобразится NULL.
В примере (п.2) показан запрос «Список зданий, с информацией о помещениях в них». Отображаются все здания, даже если в нет учтенных помещений.
Основными являются объекты, указанные первыми (слева). В примере — это здания. Если вдруг нужно изменить порядок соединения, а переписывать запрос не хочется, то можно использовать правое (RIGHT JOIN или RIGHT OUTER JOIN). Тогда основными объектами станут помещения.
В примере (п.3) в двух равнозначных вариантах показан запрос «Список помещений с информацией о зданиях, в которых они расположены». Отображаются все помещения, даже если нет соответствующего учтенного здания.
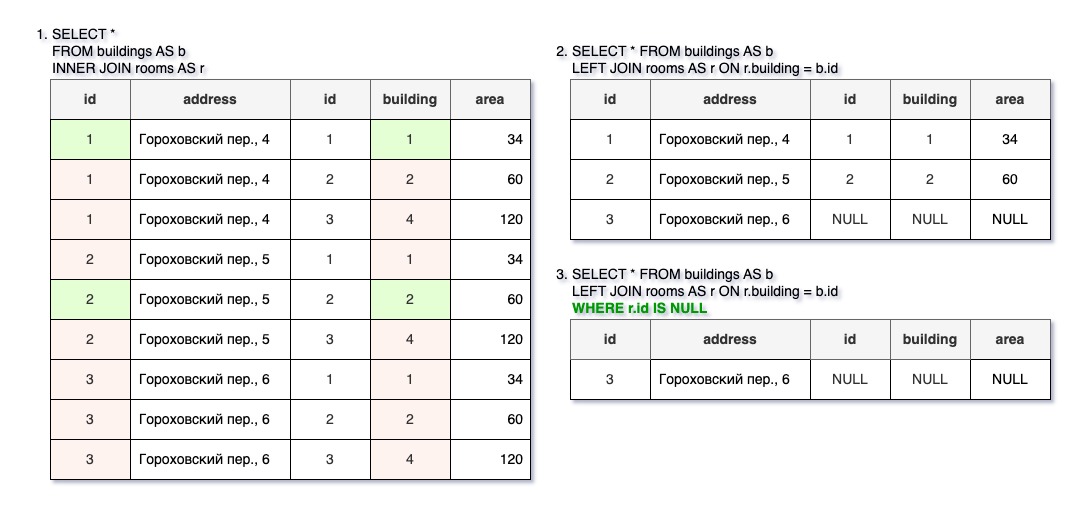
Мы можем комбинировать самые разные условия и функции. Например, запрос «Здания, в которых нет учтенных помещений» будет выглядеть следующим образом (так называемое вычитание):
SELECT * FROM buildings AS b
LEFT JOIN rooms AS r ON r.building = b.id
WHERE r.id IS NULL;
Тест №4
По подписке- Нереляционная база данных (non-relational database, NoSQL)
База данных, не следующая реляционной модели.
- Нереляционная модель данных (non-relational model)
Логическая модель данных, не следующая реляционной модели хранения и обработки данных, например: столбец, разреженная таблица, ключ-значение, документ-ключ и графические модели.
- Блокчейн (Blockchain)
Вид децентрализованной базы данных, которая хранит информацию в блоках, связанных между собой в хронологически выстроенную цепочку.
Мы можем хранить в любой базе данных информацию в двух видах:
- записи о состоянии объекта, то есть значения его характеристик, на момент времени;
- записи об изменениях характеристик. Такие записи называют транзакциями.
Допустим, мы будем записывать в базу данных сведения об изменениях характеристик объектов недвижимости. В этом случае мы можем при необходимости рассчитать и проверить текущие значения характеристик, последовательно пройдя по истории всех транзакций от самого начала ведения записей.
Нам нужно быть уверенными, что никто не изменил сохраненные данные. В случае с блокчейном это задача решается так: в каждую последующую запись включается хэш от предыдущей. Что такое хэш? Хэш — это выглядящий беспорядочным набор символов. Он получается из исходных данных посредством односторонней математической функции и обладает весьма интересными особенностями:
- хэш можно получить из любых данных, но из хеша их нельзя восстановить обратно;
- если в исходных данных изменить хотя бы на один символ, хэш будет совсем другим;
- вероятность коллизии, то получения одинакового хэша из разных исходных данных статистически невероятна.
Таким образом учет хэшей делает невозможным изменение уже сохраненных данных. При этом зачастую несколько транзакций объединяют в один блок данных — что-то вроде страницы, состоящей из отдельных строчек. В каждый блок включается хэш от предыдущего блока. Так в результате и получается цепочка блоков или блокчейн.
Правом на добавление новых записей обладают участники сети, у которых есть соответствующие сертификаты и ключи для электронного подписания. В случае с ЕГРН при наличии контрактов таким правом могли бы обладать не только регистраторы, но и кадастровые инженеры, и даже сами правообладатели недвижимости.
Также в теории блокчейн подразумевает децентрализованность и распределенность хранения данных. То есть копия всей базы данных хранится не в одном ведомственном дата-центре, а в идеале любое лицо может скачать её себе, причем в беспрерывно синхронизируемом виде. В случае с государственным информационным реестром на это рассчитывать, наверное, не стоит. Скорее такие узлы сети будут у крупных участников, например у налоговой службы, банков и так далее.
В зависимости от системы, от пользователей может требоваться предоставление данных о себе, либо использование сервиса может быть абсолютно анонимным за счет применения случайных идентификаторов. В этом случае практически невозможно восстановить доступ к данным при утере аутентификаторов.
В российском законодательстве блокчейн относится к технологиям распределенного реестра.

- Семантическая сеть
Представление знаний, основанное на понятиях, в котором объекты или состояния представляются узлами, соединенными дугами, которые показывают отношения между узлами.
- Онтология
Описание множества объектов и связей между ними (концептуализация предметной области), разделяемая определённым сообществом. Формируется на формальном языке.
Не путать с антологией и антропологией.
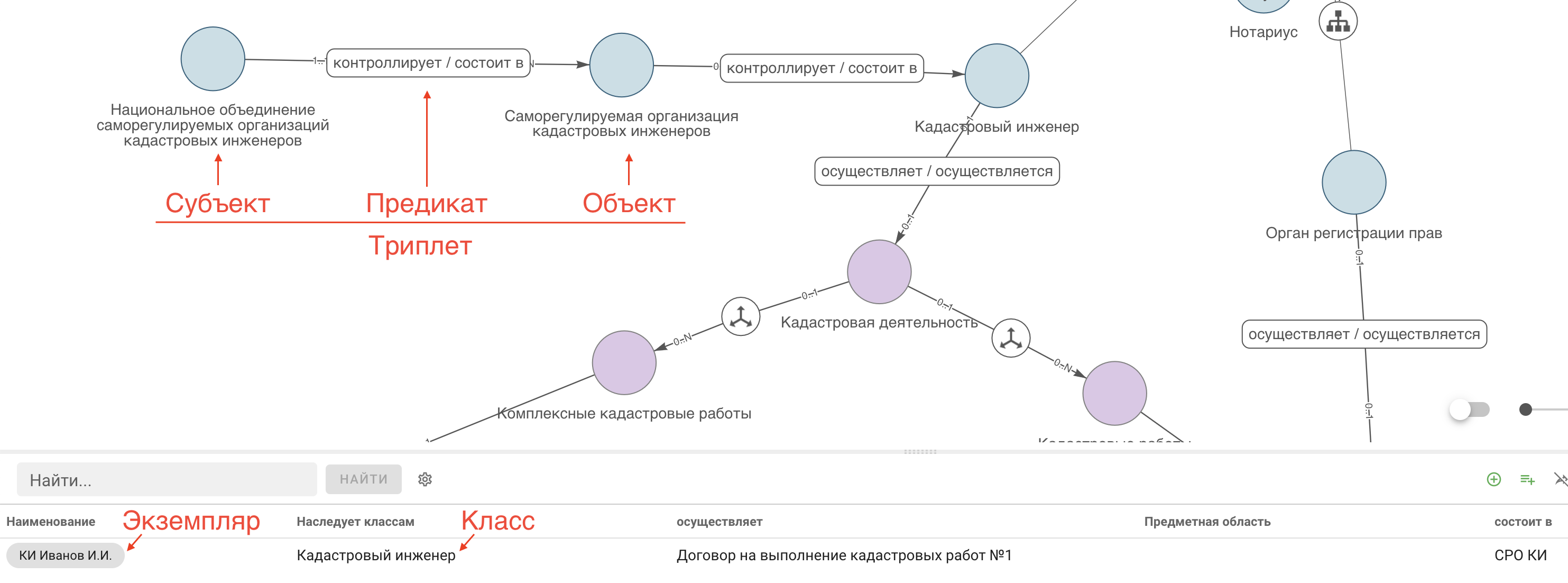
Наиболее распространены стандарты описания онтологий RDF и OWL. Ключевыми понятиями являются «субъект», «предикат», «объект», «триплет», «класс», «отношение», «экземпляр», «суждение».
В качестве примера можно привести онтологию ФНС, предназначенную для описания выписок из реестров ЕГРЮЛ и ЕГРИП.

Онтологиям высшего уровня посвящены:
- ГОСТ Р ИСО/МЭК 21838-1-2021 «Требования»;
- ГОСТ Р 59798-2021 «Базисная формальная онтология (BFO)».
- Экземпляр
В концепции Индустрии 4.0 — конкретная сущность, которая имеет свойства и проявления определенного типа.
Последние события:
- 06.2022 — ФГБУ «Центр геодезии, картографии и ИПД» объявил конкурс на 39,75 млн руб. на предоставление права использования программной платформы онтологического проектирования (в целях разработки НСПД);
- 12.2022 — ФГБУ «Центр геодезии, картографии и ИПД» выполнил первый этап работ по созданию отраслевой онтологии.

- База знаний (knowledge base)
База данных, которая содержит правила логических выводов и информацию о человеческом опыте и знаниях экспертов в предметной области.
Создание отраслевых баз знаний планируется в рамках доменов НСУД.
- Знания
В информационных технологиях — совокупность фактов, событий, убеждений, а также правил, организованных для систематического применения.
- Экспертная система (система, основанная на знаниях, KBS)
Система обработки информации, которая обеспечивает решение задач в конкретной области или сфере приложений путем логических выводов, извлекаемых из базы знаний.
Тест №5
По подписке- Open Geospatial Consortium (OGC)
Международная некоммерческая организация, ведущая деятельность по разработке стандартов в сфере геопространственных данных и сервисов, в том числе:
- GeoTIFF;
- GML;
- KML;
- SFA;
- WFS;
- WMS.
Ранее организация именовалась Open GIS Consortium.
Официальный сайт: https://www.ogc.org
- Simple feature access OGS
Стандарт OGC, также именуемый ISO 19125, описывающий методику и формат описания простых геометрических объектов.
Официальный сайт: https://www.ogc.org/standards/sfa
Перевод: https://gis-lab.info/docs/ogc-sfa-1.htmlВ стандарт входит раздел Simple feature SQL (SFS), в котором описано расширение SQL, которое поддерживает хранение, поиск, запрос и обновление геопространственных объектов с простой геометрией в реляционной базе данных.
Официальный сайт: https://www.ogc.org/standards/sfs
- Точечный объект (точка)
Нульмерный пространственный объект, координатные данные которого состоят из единственной пары плановых координат.
- Линейный объект (линия, полилиния)
Одномерный пространственный объект, координатные данные которого состоят из двух или более пар плановых координат, образуя последовательность из одного или более сегментов.
- Полигональный объект (полигон, область)
Двухмерный пространственный объект, ограниченный замкнутым линейным объектом и обычно идентифицированный своим центроидом
- Поверхность
Двухмерный пространственный объект, образованный в своих границах набором значений функции двухмерных координат в виде непрерывного поля.
- Геометрический примитив
Тип пространственного объекта с присущими ему геометрическими свойствами и размерностью, рассматриваемый как неделимый.
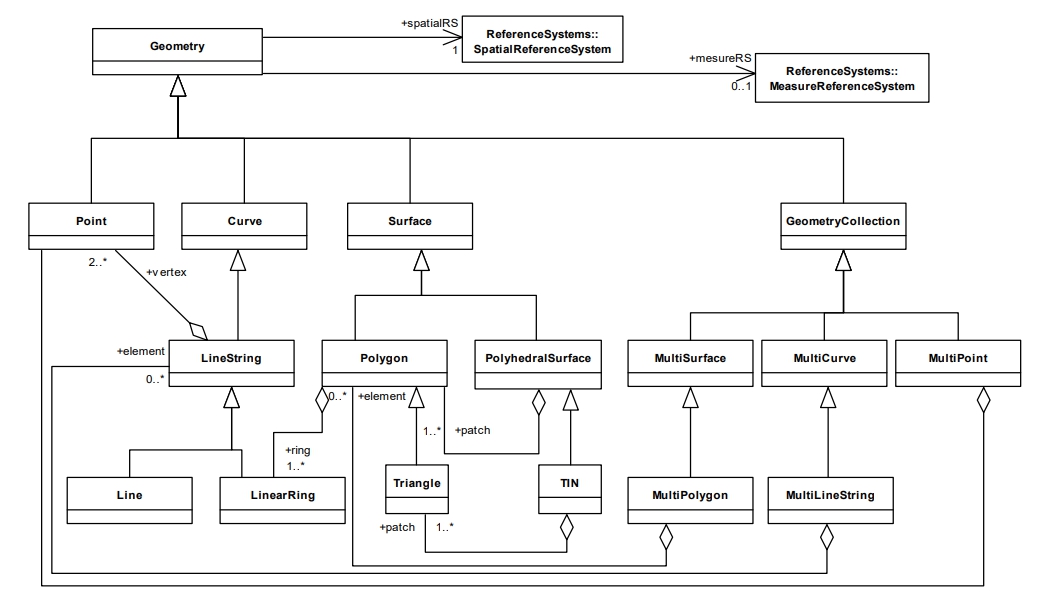
Стандартом SFA OGS предусмотрены типы объектов:
- Geometry (корневой абстрактный класс):
- Point (размерность 0, одна позиция в пространстве);
- Curve (размерность 1, последовательность Point):
- LineString (Curve с линейной интерполяцией между точками. Каждая последовательная пара точек определяет объект Line):
- Line;
- LineRing;
- LineString (Curve с линейной интерполяцией между точками. Каждая последовательная пара точек определяет объект Line):
- Surface (размерность 2);
- Polygon (плоская поверхность, задаваемая при помощи одной внешней границы и 0 или более внутренних);
- PolyhedralSurface (многогранная поверхность является набором граничащих по внешней границе полигонов);
- GeomCollection (объект, содержащий несколько других объектов):
- MultiCurve (сейчас не используется):
- MultiLineString;
- MultiSurface:
- MultiPolygon;
- MultiPoint (состоит из Point, которые не соединены между собой и порядок их следования не важен).
- MultiCurve (сейчас не используется):
Согласно Приказу Минэкономразвития России от 28.02.2023 №123 в документах территориального планирования объектов федерального, регионального и местного значения при описании пространственных данных могут применяться следующие типы геометрий:
- точка (Point);
- линия (Line);
- кривая (Curve);
- полигон (Polygon);
- мультиточка (Multipoint);
- мультикривая (MultiCurve);
- мультиполигон (MultiPolygon).
- Формат WKT (Well-known text)
Текстовый формат координатного описания пространственных объектов, используемый при реализации стандартов OGS.
Для хранения данные из текстового вида часто преобразуются в двоичное представление в шестнадцатеричных строках в формате WKB (Well-known binary), например:
- WKT: POINT(2.0 4.0);
- WKB: 000000000140000000000000004010000000000000, где:
- 1-byte integer 00 или 0: прямой порядок байт;
- 4-byte integer 00000001 или 1: POINT (2D);
- 8-byte float 4000000000000000 или 2.0: x-координата;
- 8-byte float 4010000000000000 или 4.0: y-координата.
Существуют расширенные версии формата:
-
EWKT (Extended) используется в PostGIS и включает до 4-х значений координат (XYZM);
-
AGF используется в продуктах Autodesk и включает кривые.
Форматы WKT и WKB используются в том числе для представления геометрии при размещении данных в АИС «Цифровой двойник» Москвы в рамках цифрового мастер-планирования.
Таблица — Пространственные типы данных в СУБД MySQL
| Тип поля | Комментарий | Описание в формате WKT | Команда SQL |
GEOMETRY | Объект любого типа | ||
| POINT | POINT(15 20) | Point(15, 20) | |
| LINESTRING | LINESTRING(0 0, 10 10, 20 25, 50 60) | LineString(pt [, pt] ...) | |
| POLYGON | POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5)) | Polygon(ls [, ls] ...) | |
| MULTIPOINT | Коллекция POINT | MULTIPOINT(0 0, 20 20, 60 60) | MultiPoint(pt [, pt2] ...) |
| MULTILINESTRING | Коллекция LINESTRING | MULTILINESTRING( (10 10, 20 20), (15 15, 30 15) ) | MultiLineString(ls [, ls] ...) |
| MULTIPOLYGON | Коллекция POLYGON | MULTIPOLYGON( ((0 0,10 0,10 10,0 10,0 0)),((5 5,7 5,7 7,5 7, 5 5)) ) | MultiPolygon(poly [, poly] ...) |
| GEOMETRYCOLLECTION | Коллекция объектов любого типа | GEOMETRYCOLLECTION( POINT(10 10), POINT(30 30), LINESTRING(15 15, 20 20) ) | GeometryCollection(g [, g] ...) |
В MySQL описание геометрии в формате WKT преобразуется для использование в запросах в сооветствующее выражение на SQL с помощью специальных функций, так:
Point(15, 20) — это то же самое, что ST_GeomFromText('POINT(15 20)')
Каждый объект обладает свойствами:
- тип;
- идентификатор пространственной привязки SRID:
- 0 - бесконечная плоскость;
- координаты;
- минимальный ограничивающий прямоугольник MBR ((MINX MINY, MAXX MINY, MAXX MAXY, MINX MAXY, MINX MINY));
- является ли пустой (нет точек, площадь 0);
- размерность:
-1 для пустой геометрии;
0 для геометрии без длины и без области;
1 для геометрии с ненулевой длиной и нулевой площадью;
2 для геометрии с ненулевой площадью;
- внутренняя область, границы и внешняя область.
Требования к геометрии для корректной работы функций:
- линия имеет как минимум две точки;
- полигоны имеют как минимум одно кольцо;
- кольца многоугольника замкнуты (первая и последняя точки совпадают);
- кольца многоугольника имеют как минимум 4 точки;
- коллекции не пусты (кроме GeometryCollection);
полигоны не являются самопересекающимися;
внутренние кольца многоугольника находятся внутри внешнего кольца;
мультиполигоны не имеют перекрывающихся полигонов.
Операции отношения — это логические методы, которые используются для определения существования заданных пространственных топологических отношений между двумя геометрическими объектами.
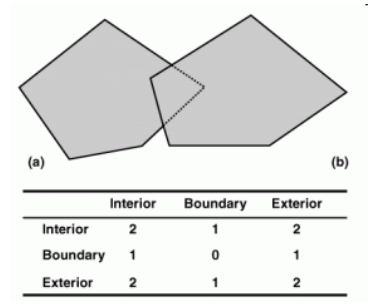
При сравнении двух геометрических объектов выполняются проверки на пересечение между их внутренними областями, их границами и внешними областями. Внутренняя область при этом содержит точки, которые покинут ее, если граница будет убрана, а внешняя — точки, которые отсутствуют и в границе и во внутренней области.
Полученные пространственные отношения классифицируются при помощи полученной матрицы пересечений размерности 3 на 3, которую именуют DE-9IM.
На иллюстрации показан пример матрицы для перекрывания (overlap) полигонов, где численные значения показывают максимальную размерность элементов, образуемых при пересечениях внутренних областей, границ и внешних областей.
Для более удобной работы предусмотрены именованные случаи матрицы в виде операций (методов) определения отношений между объектами: equals, intersects и другие.
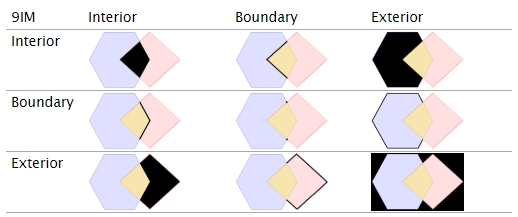
Если мы применим настоящую теорию к кадастру, то сможем дать формальные определения:
- смежными земельными участками являются такие, для которых одновременно выполняются условия:
- dim[I(a) ∩ I(b)] = -1
- dim[B(a) ∩ B(b)] = 0 ∨ 1
- пересекающимися земельными участками являются такие, для которых выполняется условие:
- dim[I(a) ∩ I(b)] = 2
О пересечениях в 3D см. работу Zlatanova S. (2015) Topological Relationships and Their Use. In: Shekhar S., Xiong H., Zhou X. (eds) Encyclopedia of GIS. Springer, Cham. https://doi.org/10.1007/978-3-319-23519-6_1548-1
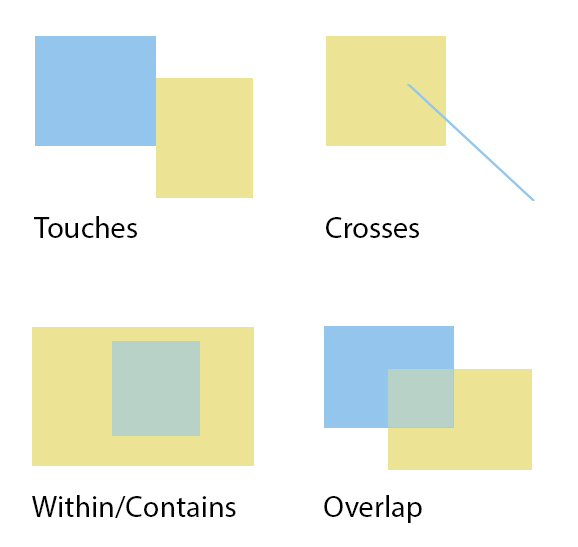
Таблица — Методы определения пространственного взаимоположения объектов SFA
| Операция | Описание | Соответствующая команда в MySQL | Соответствующая команда в MapInfo/Axioma |
| Equals | объект равен другому (совпадает) | ST_Equals(g1, g1) | |
| Disjoint | объект не пересекается с другим | ST_Disjoint(g1, g2) | |
| Intersects | объект любым способом пересекается с другим (обратное от Disjoint) | ST_Intersects(g1, g2) | Where A.object Intersects B.object Синонимы: "Contains Part" и "Partly Within" |
| Touches | объект соприкасается с другим | ST_Touches(g1, g2) | |
Crosses | объект пересекает границу другого (перекрещивается). Размерность пересечения должна быть на 1 менее максимальной. | ST_Crosses(g1, g2) | |
Within | объект находится внутри другого | ST_Within(g1, g2) | Where A.object Within B.object Where A.object Entirely Within B.object |
Contains | объект полностью содержит другой (обратное от Within) | ST_Contains(g1, g2) | Where A.object Contains B.object Where A.object Entirely Contains B.object |
Overlaps | объект накрывает собой часть другой. Пересечение той же размерности, но не равной ни одной из исходных геометрий. | ST_Overlaps(g1, g2) | |
Relate | объект соответствует топологическому отношению с другим объектом, заданному при помощи матрицы. Проверяются пересечения между внутренними и внешними частями объектов, границами объектов | ||
LocateAlong | Возвращает геометрический объект, содержащий все точки с заданной координатой m | ||
LocateBetween | Возвращает геометрический объект, содержащий все точки, координата m которых находится в заданном диапазоне |
- Центроид
В MapInfo — центр графического объекта на карте, который совпадает с центром описанного вокруг объекта прямоугольника, за исключением случаев, когда он попадает вне объекта,
В Бразилии исследователи предложили включать координаты центроида в кадастровый номер.
Примеры SQL запросов для СУБД MySQL:
- INSERT INTO t1 (pt_col) VALUES(Point(1,2));
- INSERT INTO geom VALUES (ST_GeomFromText('POINT(1 1)'));
- SELECT ST_AsText(g) FROM geom;
- SELECT ST_Contains(polygon, point) FROM geom;
- SELECT ST_Area(poly) FROM `buildings`;
Для запросов следует создавать индексы типа SPATIAL.
Таблица — Некоторые пространственные функции SFA
| Операция | Описание | Пример запроса SQL | Соответствующая команда в MySQL | Соответствующая команда в MapInfo/Axioma |
|---|---|---|---|---|
| Area | Площадь | SELECT Area(shores) FROM ponds WHERE fid = 120; | ST_Area(geometry) | Area(obj, unit) |
| Length | Длина | SELECT Length(centerlines) FROM divided_routes WHERE name = 'Route 75'; | ST_Length(geometry) | ObjectLen(obj, unit) Perimeter(obj, unit) |
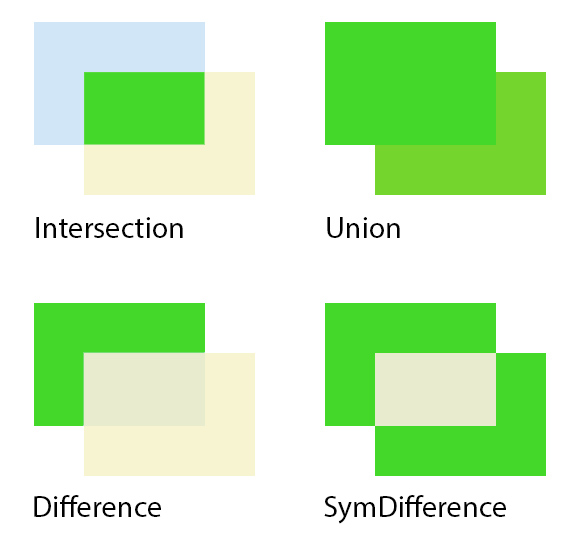
Таблица — Методы пространственных построений SFA
| Операция | Описание | Соответствующая команда в MySQL | Соответствующая команда в MapInfo MapBasic |
|---|---|---|---|
| Distance | Возвращает кратчайшее расстояние между объектами (между двумя ближайшими точками контуров объектов) | ST_Distance(g1, g2) |
Select Distance(OriginX, OriginY, DestX, DestY, units) From table; |
| Buffer | Возвращает геометрический объект, все точки которого находятся от объекта на расстоянии, меньше или равно заданному | ST_Buffer(geometry, distance, type) |
Create Object As Buffer From table; Select Buffer(table.obj, 100, 20, "km" ) |
| ConvexHull | Возвращает геометрический объект, представляющий ограничивающий данный объект выпуклый многоугольник (из прямых линий) |
ST_ConvexHull(geometry) | Create Object As ConvexHull From table; |
| Intersection | Возвращает геометрический объект, содержащий набор точек фигуры, образованной пересечением объектов | ST_Intersection(g1, g2) |
Create Object As Intersect From table; Select Overlap(table1.object, table2.object) From table1, table2; |
| Union | Возвращает геометрический объект, содержащий набор точек фигуры, образованной объединением объектов |
ST_Union(g1, g2) |
Create Object As Union From table; Create Object As Merge From table; |
| Difference | Возвращает геометрический объект, содержащий набор точек фигуры, образованной вычитанием одного объекта из другого | ST_Difference(g1, g2) | |
| SymDifference | Возвращает геометрический объект, содержащий набор точек фигуры, образованной симметрической разностью объектов (обратное от Difference). Симметричной называется, потому что не играет роли, что из чего вычитается. |
ST_SymDifference(g1, g2)
то же самое, что
ST_Difference(ST_Union(g1, g2), ST_Intersection(g1, g2)) |
|
Тест №6
По подписке
Цитирование
Справочник является объектом авторских прав. При использовании материалов следует указывать в источниках библиографическое описание:
Базы данных (Проектирование реестра недвижимости). – Текст : электронный // Справочник кадастрового инженера Cadastre.ru : монография / С. А. Атаманов, С. А. Григорьев, З. С. Косаруков, М. С. Чуприн. – Москва, 2024. – URL: http://cadastre.ru/article/12 (дата обращения: 21.11.2024).
Проект поддерживают
Кадастр.Москва
Факультет управления территориями МИИГАиК
Texplan.ru
PlanTracer
Лаборатория
Градостроительный калькулятор
Онлайн-сервис для расчета и проверки на соответствие требованиям суммарной поэтажной площади, плотности застройки и процента застройки земельного участка
Оценка качества пространственных данных
Онлайн-сервис для формирования отчетов об оценке качества согласно ГОСТ Р 57773-2017 (ИСО 19157:2013)
Расчет площадей и погрешностей (П/0393)
По приказу Росреестра №П/0393 от 23.10.2020 площадь определяется на основании натурных измерений такого объекта как площадь простейшей геометрической фигуры или путем разбивки на фигуры и суммирования их площадей. Для оценки точности определения (вычисления) площади рассчитывается средняя квадратическая погрешность
Тестирование на знание терминологии
Справочник содержит множество определений, используемых в градостроительстве, при кадастровом учете и регистрации прав. Проверьте себя на их знание. За каждый правильный вопрос начисляется 1 балл, за неправильный снимается. Наберите 30 для получения сертификата
Граф терминов
Узлами графа являются термины, а ребра построены на основе внутренних ссылок в определениях. Отдельные узлы кластеризуются по тематике
API Справочника
Полученные по API данные могут быть использованы как разъясняющие сопровождающие или исходные материалы в указанных при получении ключа доступа коммерческих или некоммерческих информационных системах (включая приложения), производных материалах
Персональная онтология
В Справочнике реализована возможность «собирать» термины в персональную концептуальную схему, семантическую сеть — это граф, где отраслевые термины представлены узлами, а связи между ними символизируют отношения, смысл которых вы определяете и задаете самостоятельно. В результате у вас постепенно формируется личная база знаний из взаимосвязанных ключевых отраслевых понятий.
Cимулятор деятельности кадастровой организации
Конкуренция за кадры и заказы с другими компаниями, навыки и учет времени сотрудников, проектирование бизнес-процессов услуг, подбор и обустройство офиса, закупка мебели и оборудования, разработка сайта и продвижение, учет доходов и расходов, налогов, сообщения от сотрудников и заказчиков, рейтинг компаний, карта
Хронология учета недвижимости в России с 1990 года по настоящее время
Мы решили зафиксировать отраслевые события, произошедшие за период с 1990-го года по текущее время, в виде хронологии. В первую очередь нас интересует кадастровый учет, регистрация прав, мониторинг и землеустройство, в какой-то мере геодезия и картография, градостроительство и учет природных ресурсов. За эти годы много раз изменилась структура органов исполнительной власти, одни государственные информационные ресурсы и системы постепенно заменялись другими.
О сайте
Если вы первый раз на этом сайте, пожалуйста ознакомьтесь с разделом «О справочнике».
Вы можете создавать топики на любые темы, связанные с учетом недвижимости и регистрацией прав.
Все новые топики попадают на главную страницу, где их видят все посетители. Вы можете пользоваться этим, чтобы быстрее получать ответы на свои вопросы по нюансам выполнения работ.
Просьба сообщать о найденных ошибках, а также присылать имеющиеся у вас наработки и документы, которые позволят улучшить справочник, на npogeo@gmail.com
Доступ к справочнику с помощью Алисы в приложениях Яндекса (видео-обзор)

Обсуждение
Вы можете задать здесь свой вопрос по этой теме

Что происходило в отрасли учета недвижимости на неделе 13.11.24 — 19.11.24
Интересные статьи за неделю

Аренда прилегающего участка леса
В Государственную Думу внесен законопроект №758498-8 о внесении изменений в Лесной кодекс
Что происходило в отрасли учета недвижимости на неделе 06.11.24 — 12.11.24
Интересные статьи за неделю
Новая попытка вернуться к общественным обсуждениям и публичным слушаниям
В Государственную Думу внесен законопроект №702401-8

Что происходило в отрасли учета недвижимости на неделе 30.10.24 — 05.11.24
Интересные статьи за неделю
Журнал Учет недвижимости №70 (10.2024) [Скачать PDF]
Ежемесячное издание о кадастровом учёте и регистрации права
Переход на реестровую модель в градостроительстве
В Государственную Думу внесен законопроект №751791-8
Что происходило в отрасли учета недвижимости на неделе 23.10.24 — 29.10.24
Интересные статьи за неделю
- На главную
- О справочнике
- Основные понятия. Ликбез
- Классификация (типология) объектов недвижимости
- Структурные части зданий (конструктивные элементы)
- Определение контура
- Определение площади (до 2021 года)
- Определение площади (с 2021 года)
- Отступы от границ участка
- Ошибки при подготовке кадастровой документации
- Геодезическое и картографическое обеспечение
- Этажность и количество этажей
- Понятия, не вошедшие в другие разделы
- Курьезы
- Все термины и определения (A-Я)
- Последние обновления
- Источники (НПА)
- Лаборатория
- Поиск
- Кадастровая деятельность
- Организация кадастровой деятельности
- Специализированное ПО для кадастровых инженеров
- Информационные системы и сервисы
- Информационное моделирование объектов строительства
- Землеустройство, охрана и мониторинг земель
- Государственный учет лесных ресурсов
- Государственный учет водных ресурсов
- Недропользование
- Градостроительная деятельность
- Кадастровый учет и регистрация прав
- Качество пространственных данных
- Государственный учет жилищного фонда
- Структура и содержание ФГИС ЕГРН
- Национальная система пространственных данных
- Кадастровый аудит
- Заметки по ситуациям, амнистиям
- Базы данных (Проектирование реестра недвижимости)
- Электронная подпись
- Цифровая трансформация
- Советы по оформлению документации
- Сводное тестирование
Подсказка: нажмите на верхний (надстрочный) индекс, чтобы открыть всплывающую панель с поясняющей связанной информацией
